[네부캠 멤버십 스프린트] 1주차 ~ 7주차 정리
스프린트 1주차 학습정리
(DOM, SPA, Flex, css…)
HTML5 Layout Tag
Html5 레이아웃 태그에는 6가지 정도가 있다.
header : 페이지 상단의 머릿말을 정의
nav : 네비게이션(메뉴), 사이트 내의 다른 페이지로 이동
aside : 카테고리, 현재 페이지 외의 컨텐츠
main : 가장 중요한 핵심 컨텐츠를 감싸는 태그, 한 페이지에 하나 사용, 강조의 느낌
section : 페이지의 주요 컨텐츠를 구분하는 태그
article : 독립적인 하나의 컨텐츠, 예시) 이름처럼 블로그 글이나 뉴스 기사
footer : 페이지 최하단의 부가 정보, 예시) 저작권, 연락처, 사이트맵 등등
DOM(Document Object Model)
DOM 의 개념
DOM 은 HTML, XML 문서의 프로그래밍 interface 이다. 각 브라우저마다 이 인터페이스를 구현해서 저마다의 DOM 을 가지고 있다.
웹 페이지는 일종의 문서(document) 이다. DOM 은 이 문서를 트리 구조로 만들어서(구조화) 제공하며 이렇게 구조화된 정보를 바탕으로
프로그래밍 언어가 동적으로 문서의 구조, 스타일, 내용 등을 변경할 수 있게 돕는다.
DOM 은 nodes 와 objects 로 문서를 표현한다.
DOM tree 에서 모든 요소는 전부 `node` 로 표현된다. HTML 태그, 텍스트, 속성(attribute) 등은 전부 하나의 노드이다.
=> `node` 는 문서를 구조적으로 표현하는 단위이다.
`object` 는 노드에 대한 실제 프로그래밍 인터페이스이다.
객체는 노드를 조작할 수 있는 인터페이스를 제공함으로써 프로그래밍 언어가 문서와 문서의 요소에 접근할 수 있도록 한다.
=> `object` 는 노드에 대한 접근을 제공한다.
만약 DOM 이 없다면 프로그래밍 언어(js 등)은 문서(웹 페이지 or XML 페이지) 및 페이지의 요소들과 관련된 모델이나 개념들에 대한 정보를 얻을 수 없다. (문서에 접근할 수 없다)
초기에는 자바스크립트와 DOM 이 밀접하게 연결되어 있었으나 이제는 프로그래밍 언어와 독립적으로 디자인되었다. 따라서 어떠한 언어에서도 DOM 을 구현할 수 있다.
DOM 의 핵심 인터페이스
- document.getElementById(id)
- document.getElementsByTagName(name)
- document.createElement(name)
- parentNode.appendChild(node)
- element.innerHTML
- element.style.left
- element.setAttribute
- element.getAttribute
- element.addEventListener
- window.content
- window.onload
- window.dump
- window.scrollTo
DOM 의 렌더링 과정
위의 영상을 참고해서 작성했습니다.
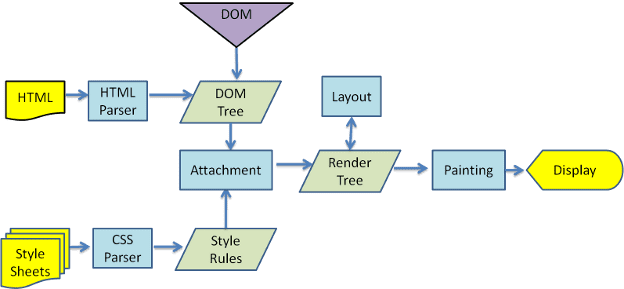 image.png
image.png
- HTML 을 파싱해서
DOM node 트리를 생성 - 스타일 정보를 추가하여
Render tree생성 - 각 노드들의 배치할 위치를 결정(Layout)
- 각 요소에 색상을 입히기(Painting)
DOM 조작
DOM을 조작할 때는 위에서 말한 렌더링 과정 전체를 다시 수행한다.
이때문에 아주 작은 변경이 있더라도 전제를 렌더링하기 때문에 상당히 비효율적이다.
렌더링 과정은 상당히 값비싼 과정이기 때문에, 매번 이 과정을 수행하는것은 변경 사항에 비해 너무 무거울 수 있다.
정적인 페이지는 DOM 에 대한 조작이 별로 없기 때문에 이런 DOM 조작 방식이 괜찮을 수 있다.
하지만 하나의 페이지로 필요한 데이터들을 바꿔가며 화면에 띄워주는 SPA(Single Page Application) 에는 이런 DOM 방식은 너무나도 비효율적일 것이다.
SPA(Single Page Applcation)
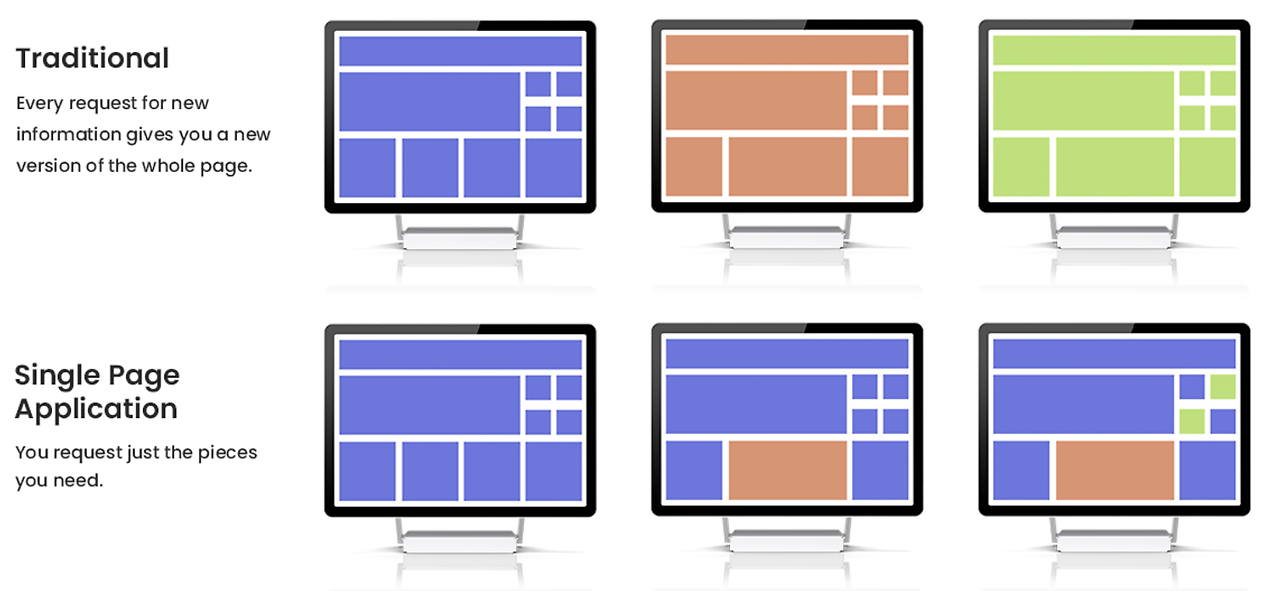 image.png
image.png
렌더링을 Client , Server 중 어디서 하는지에 따라 우리는 CSR(Client Side Rendering), SSR(Server Side Rendering) 이라고 부른다.
SSR 에서는 서버가 페이지의 모든 부분을 렌더링해서 html를 클라이언트에게 넘겨주기 때문에, 클라이언트는 받은 html 을 reload 해서 렌더링한다.
반면 CSR 에서는 클라이언트가 직접 필요로 하는 부분의 데이터만 ajax 방식으로 서버에 요청해서, 받은 데이터 부분만 다시 렌더링하는 방식이다.
Flexbox
Flexbox 의 개념
flexbox 는 아이템간 공간 배분과 강력한 정렬 기능을 제공하기 위한 1차원 레이아웃 모델
1차원이라 칭하는 이유는, 레이아웃을 다룰 때 한 번에 하나의 차원만 다룬다는 뜻이다.
이는 행만 다루거나, 열만 다룬다는 의미다.
이후에 공부해야 할 Grid 레이아웃은 2차원 모델이다.
주축과 교차축
flexbox 에는 flex-direction 속성을 사용하여 주축 을 설정하고, 주축에 수직인 축이 교차축 으로 설정된다.
flex 되는 아이템들은 주축을 기준으로 배치 되고, 교차축을 기준으로 정렬 된다.
주축
- row (
가로, 아이템이 왼쪽에서 오른쪽으로 배치) - row-reverse (
가로, 아이템이 오른쪽에서 왼쪽으로 배치) - column (
세로, 아이템이 위에서 아래로 배치) - column-reverse (
세로, 아이템이 아래에서 위로 배치)
교차축
교차축은 주축에 수직이다.
| 따라서 주축이 가로(row | row-reverse) 라면 교차축은 세로이고, |
| 주축이 세로(column | column-reverse) 라면 교차축은 가로이다. |
Flex 컨테이너
문서의 영역 중에서 flexbox가 놓여있는 영역을 flex 컨테이너라고 부릅니다.
flex 컨테이너를 생성하려면 영역 내의 컨테이너 요소의 display 값을 flex 혹은 inline-flex로 지정합니다.
이 값이 지정된 컨테이너의 일차 자식(direct children) 요소가 flex 항목이 됩니다
여기서 일차 자식이란 부모의 바로 밑 자식을 의미한다. 할머니에게 있어서 손자는 일차 자식이 아닌 이차 자식이다.
flex-wrap
flex-box 는 1차원 모델이지만 flex 항목이 여러 행/열에 나열되도록 할 수 있습니다
flex-box 에 있는 flex 항목은 가로 혹은 세로로만 배치되는 1차원 모델이다. 다만 다음 가로줄 혹은 다음 세로줄에 배치되도록 해주는 속성이
flex-wrap 이다.
css
.box {
display: flex;
flex-direction: row;
flex-wrap: wrap;
}
 image.png
image.png
아이템이 하나의 행에 들어가지 않을 정도로 크다면, 다음 행에 배치되는 모습을 볼 수 있다.
css
.box {
width: 500px;
height: 550px;
display: flex;
overflow: scroll;
flex-direction: column;
flex-wrap: wrap;
}
div {
width: 50px;
height: 150px;
}
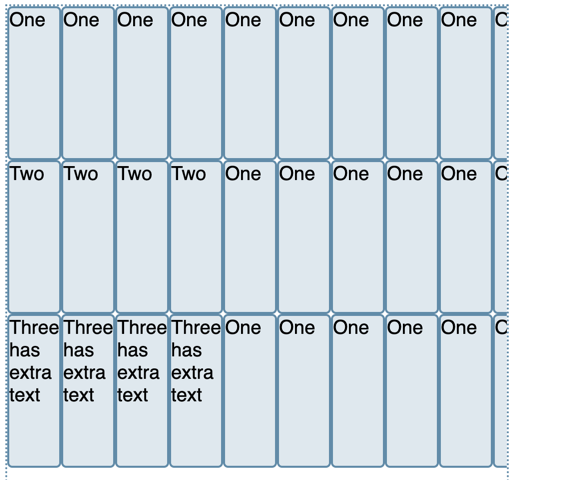 image.png
image.png
아이템이 하나의 열에 들어가지 않을 정도로 크다면, 다음 열에 배치되는 모습을 볼 수 있다.
참고
궁금증
html
<div id="header" role="banner"></div>
<div id="container" role="main"></div>
<div id="footer" role="contentinfo"></div>
네이버 메인 화면의 layout 영역인데, 직접 <header> 를 쓰지않고 div 로 만들었다.
이건 무슨 차이가 있을까?
=> HTML5 이전의 접근성 개선을 위함
자바스크립트가 빠른 이유 : 바이트코드 + JIT 컹파일러 넷스케이프의 스파이더몽키는 자바스크립트를 바로 인터프리터로 해석하기 때문에 속도가 느리다.
빨라져서 브라우저 바깥으로 탈출할 수 있게 되었다.
nginx – 비동기 스프링/아파치 -> 100명을 위해 멀티프로세스 혹은 멀티스레드로 처리 -> 메모리를 엄청 잡아 먹는다
nginx: 이벤트 중심 접근 방식, 하나 스레드로 여러 요청 처리 apache: 프로세스 기반 접근 방식, 매 요청마다 스레드 생성 및 할당
nodejs 가 I/O 가 빨라지는건 아니다. 커널이 처리하는거라 빨라지는건 아니고 작업의 효율성이 증가하는 것 뿐이다.
노드 JS 공식문서 읽어보기 반드시
쉘 스크립트 echo “hello”; echo “hell” echo “hello” && echo “hell” -> 앞에 리턴값이 0(성공)이면 뒤에 실행 || 는 0이 아닐때 (실패) 뒤에 실행
echo $? -> 0
top -> htop -> bpytop
동기/블로킹과 비동기/논블로킹 공부
이그니션(인터프리터) -> 바이트코드 생성 터보팬(컴파일러) -> 최적화된 기계어 코드 생성
최적화? optimizer 때문에 내가 원하는대로 작성한대로 코드가 돌아가지 않을 수 있음.
JIT 컴파일러 -> 자바에서 hotspot vm, 크롬 v8 에서 사용중 언제 나왔을까? 70년대에 나온 기술, oop의 원조는 smalltalk (GUI 프로그래밍을 하려고 제록스 연구소에 만들었다) 스몰톡도 인터프리터 언어인데, 성능을 높이려고 자주 사용하는 결과를 해싱해 놓으면 빠를 것 같아서 인터프리터 한 결과를 재사용
왜 바이트코드와 기계어 코드로 나눠지는 이유는 뭘까?
즉시 실행할때, 는 한 줄 읽고 해석하는 인터프리터가 더 빠르다
자주 사용되는, 재사용되는 코드가 있을 때 터보팬(컴파일) 사용
LibUV 가 node js 의 핵심 epoll, kqueue, etc -> 운영체제에서 i/o 비동기 처리를 위해서 커널에서 제공해주는 기능
윈도우는 iocp , 리눅스는 epoll, bsd 계열(mac) kqueue 이런것을 I/o 멀티 플렉싱을 제공해준다고 한다.
스레드의 아이오를 담당하는 객체, 소켓을 연다
리슨 소켓말고 실제로 처리하는 소켓을 만든다. -> 결국 쓰레드가 생기는거라 비효율적 여러 아이오를 하나의 쓰레드에서 처리할 수 있게 하는게 I/O 멀티플렉싱
https://oliveyoung.tech/blog/2023-10-02/c10-problem/
busy waiting -> 이벤트가 발생할때까지 무한루프 돌면서 계속 체크 (epoll 이 나오기 전, Select 방식) -> 비효율적 비동기를 위해서 cpu 자원을 사용
epoll 는 리눅스에서만 써서 윤영체제 비 표준이다.
이벤트루프가 운영체제의 도움을 받는데, 운영체제마다 다르게 동작하게 된다. (윈도우는 iocp , 리눅스는 epoll, bsd 계열(mac) kqueue )
디버깅 툴 잘 써야한다.
디버거 써야한다 개발10 디버깅90
브레이크포인트 걸고, 컨디션 잡고 …
백엔드 개발자는 개발하는 입장에서, 죽지 않는 서버가 가장 중요하다.
그리고 빨리 살리는것, 예외상황 처리 잘 하는 것 -> 탄탄한 cs 지식이 필요 운영체제, 데이터베이스, 네트워크
worker_threads를 통해 thread를 만들 때는 Thread마다 별도의 메모리 공간이 부여되는데 thread pool에서 꺼내올 때도 Worker thread마다 별도의 메모리 공간이 있나요?? 보통의 워커 쓰레드는 대부분 POSIX 쓰레드를 쓸건데, 별도의 메모리(커널의 지원을 통해) 를 가질 수 밖에 없다.
자바 쓰레드는 네이티브 쓰레드일까? 유저레벨 쓰레드일까? 자바는 커널 레벨 쓰레드이다. 자바에서 쓰레드를 하나 만들어내면 운영체제에서 쓰레드를 만들어서 매핑한다.m:n 은 다 거짓말이다.
webflux 의 쓰레드는 컨텍스트 스위칭이 일어나서 성능이 별로 안좋았음.
커널 쓰레드의 오버헤드를 개선하고 싶은데? 유저 레벨 쓰레드를 만들자 -> 자바에 버츄얼 쓰레드가 생김 문법은 똑같은데, 버츄얼 유저레벨 쓰레드가 생성되어서 성능이 대폭 향상된다.
mysql 은 X.1.10 부터 써라
Project Setting
Global
global 옵션은
devDependencies
devDependencies 는 개발할 때만 필요하고 실제 런타임에서는 필요 없는 dependency 를 의미한다.
(개발용)
TS, ESLint, Prettier
코드 품질과 괸련된 것들을 확인하는 도구를 린터(Linter) 라고 부르는데, 자바스크립트에서 사용하는 대표적인 린터가 ESLint 이다.
문법 오류를 감지하거나, 코드 품질 향상, 일관성 유지 등을 위해 적용하는데 나만의 컨벤션을 정립하기 전까지는 airbnb 스타일을 따라가보려고 한다.
shell
npm install -D eslint typescript
## airbnb 종속 패키지 설치하기
## 이렇게 종속 패키지를 한 번에 설치하면 react 관련 eslint 패키지도 설치가 되는데,
## react 를 안쓴다면 아래의 명령어로 설치하자.
npx install-peerdeps --dev eslint-config-airbnb
## React 관련 패키지 없음
npm install -D eslint @typescript-eslint/parser @typescript-eslint/eslint-plugin eslint-config-airbnb-base eslint-plugin-import eslint-plugin-node
이후에 .eslintrc.json 파일로 셋팅을 하자.
json
{
"parser": "@typescript-eslint/parser",
"extends": ["airbnb-base", "plugin:@typescript-eslint/recommended", "plugin:node/recommended"],
"plugins": ["@typescript-eslint", "node"],
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module"
},
"rules": {
"node/no-unsupported-features/es-syntax": ["error", { "ignores": ["modules"] }],
"node/no-missing-import": "off",
"node/no-unpublished-import": "off",
"import/no-unresolved": "off",
"import/extensions": [
"error",
"ignorePackages",
{
"js": "never",
"jsx": "never",
"ts": "never",
"tsx": "never"
}
]
},
"settings": {
"import/resolver": {
"node": {
"extensions": [".js", ".jsx", ".ts", ".tsx"]
}
}
}
}
shell
npm install -D @types/express
Prettier
Prettier 는 코드 형식을 자동으로 정리해주는 Formatter 의 역할을 한다. prettier 셋팅에 맞게 자동으로 정리해주기 때문에 코드의 가독성과 일관성을 챙길 수 있다.
text
ts-node
shell
npm install -D ts-node
스프린트 2주차 학습정리(MySQL, Flux)
MYSQL
- 참고자료
MYSQL 서버는 크게 MYSQL 엔진 과 스토리지 엔진 으로 나뉘게 된다.
스토리지 엔진은 과거에는 여러가지 있었으나 Mysql 8.0 버전 이후로는 InnoDB 가 기본값이 되었다고 한다.
사용자가 mysql 서버에 연결 요청을 보내면, 연결 핸들러가 이를 처리하고 세션이 생성된다.
이후에 sql 쿼리를 날리면, 크게 아래의 5단계 과정을 거쳐 정보를 가져온다.
MySQL 엔진
- 쿼리 파서
- 쿼리를 토큰으로 잘게 쪼개어 트리의 형태로 파싱하는데, 쿼리에 문법적 오류가 있는지 검사를 한다.
- 전처리기
- 전처리기는 예약어를 제외한 토큰을 검사해서 데이터베이스에 실제로 데이터가 존재하는지, 객체에 사용자가 접근할 수 있는지(권한 등) 검증
- 옵티마이저
- 넘겨받은 파스 트리를 실행 계획으로 바꾸는 역할
- 쿼리 재작성, 테이블 스캔 순서 결정, 사용할 인덱스 선택 등 최적의 실행 계획을 작성한다.
- 실행 계획은 아래와 같이 바뀌는데 id 가 같은 실행 계획이 있다면
JOIN된다는 걸 의미한다. - 최적화 하는 방법은 비용 기반 최적화와 규칙 기반 최적화가 있는데, Mysql 에 존재하는 다양한 통계 정보를 활용해서 비용을 최대한 줄이는 방향의 최적화이고 규칙 기반 최적화는 동일한 sql 이면 동일한 실행 계획을 만드는 방향의 최적화이다.(순수함수가 떠오르게 하네)
- 대부분의 RDBMS 는 비용기반 최적화이다.
- idselect_typetabletypekeyrowsextra1SIMPLEarticleindexPRIMARY5Using where1SIMPLEmemberseq_refPRIMARY1EMPTY
- 실행 엔진
- 이렇게 전달된 실행 계획을 토대로 스토리지 엔진과 통신을 해서 데이터를 읽어온다.
- 스토리지 엔진(InnoDB)
- 실행 엔진의 요청을 실제 디스크에서 처리하면서 데이터 읽기/쓰기 를 수행한다.
- 스토리지 엔진은 MySQL 엔진과 다르게 여러 개를 동시에 사용할 수 있다.
그렇다면 InnoDB 는 어떤 구조를 가질까?
스토리지 엔진
버퍼 풀
버퍼 풀은 메인 메모리의 한 영역으로 테이블과 인덱스 데이터를 캐싱 해두는 공간이다.
말 그대로 디스크보다 읽기 쓰기가 압도적으로 빠른 메인 메모리에 데이터를 캐싱해두고 디스크 읽기/쓰기 전에 버퍼 풀을 먼저 확인하는 것이다.
버퍼 풀의 데이터의 저장 단위는 여러 행을 저장할 수 있는 Page 단위인데, 그 이유는 디스크의 데이터 저장 단위가 페이지이기 때문이다.
버퍼 풀에서 페이지들은 링크드 리스트로 관리가 되는데, 이때 페이지들은 LRU(Least Recently Used) 에서 살짝 바뀐 알고리즘읉 통해 관리가 된다. 내가 알던 LRU 와 살짝 다른데, 어떤 부분이 다른지 한 번 살펴보자.
LRU 알고리즘과 버퍼 풀
17.5.1 Buffer Pool (해당 mysql 공식 문서를 참조해서 작성했다)
버퍼 풀에서 페이지들은 얼마나 자주 사용되었느냐에 따라 New Subset, Old Subset. 로 나뉘고 New Subset 과 Old Subset 이 맞닿아있는 포인트를 Middle Point 라고 한다.
원래 LRU 는 단순히 가장 오랫동안 사용하지 않은 페이지(tail 에 있는 페이지)를 제거하고, 가장 최근에 사용한 페이지를 head 에 넣는 알고리즘이다.
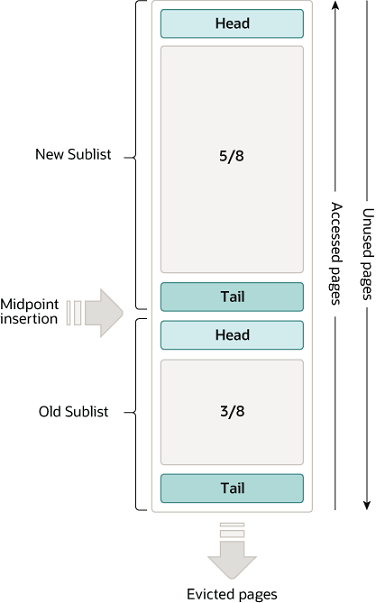 image.png
image.png
하지만 InnoDB 의 LRU 는 살짝 다른데, 위의 그림에서 보면 버퍼 풀의 $\frac{5}{8}$ 을 New Sublist, $\frac{3}{8}$ 을 Olb Sublist 로 할당하고 New Sublist 의 tail 과 Old Sublist 의 Head 가 맞닿은 곳이 바로 Middle Point 이다.
이제 사용자가 특정 페이지를 읽게 되면 Old Sublist 의 Head 로 해당 페이지가 들어가고 Old Sublist 의 tail 에 해당하는 페이지는 삭제된다.
이 시점에서 왜 New Sublist 의 Head 에 들어가는게 아니라, MidPoint 로 들어가는지 의문일 수 있다.
InnoDB 는 “처음 버퍼 풀에 등록된 페이지가 가장 최근의(중요한) 페이지라고 생각하기보다는, 첫 등록에는 아직까지 그닥 중요한 페이지가 아니다.” 라고 간주한다
페이지는 유저의 요청에 버퍼 풀에 올라올 수도 있고 아니면 InnoDB가 예측(read-ahead)해서 미리 페이지를 preload 하는 경우에도 버퍼 풀에 올라올 수 있다. (사용자가 다음엔 이걸 읽겠지? 하고 미리 로드)
사용자의 요청에 의해 Old Sublist 에 있는 페이지를 읽게되면 해당 페이지를 young 하게 만든다. 즉, 해당 페이지를 참조해서 유저에게 데이터를 주고, 바로New Sublist 의 head 로 옮겨버린다.
그러나 InnoDB 의 read-ahead 에 의해 버퍼 풀에 올라온 페이지는 말 그대로 예측이기 때문에 유저가 참조하지 않을 수도 있다.
따라서 당연하게도 read-ahead 로 올라온 페이지는 유저에 의해 참조될 수도, 아니면 그대로 계속 순위기 밀려 제거될 수도 있다.
새로운 페이지가 등장하면 Old Sublist 들의 페이지는 전부 노화(사용 순위가 밀림)한다.
만약 Old Sublist 에 존재하는 페이지가 참조되면서 Sublist 의 Head 로 올라가게 되면, 이 페이지를 제외한 나머지 페이지들도 모두 노화한다.
그렇게 노화하다가 Old Sublist 의 tail 에 도달한 페이지는 제거된다.
MYSQL 셋팅과 문제 해결
기존에 사용하던 ubuntu 24.04 가상머신을 그대로 활용했다. M1 맥 위에 설치한 가상머신이라서 aarch64 아키텍처이다.
MySQL 8.0.XX 버전 설치하기
우선 APT 저장소에서 다운받을 수 있는 버전을 확인하고 가장 최신 버전으로 다운 받았다.
shell
apt-cache policy mysql-server
# mysql-server:
# Installed: 8.0.39-0ubuntu0.24.04.2
# Candidate: 8.0.39-0ubuntu0.24.04.2
# Version table:
# *** 8.0.39-0ubuntu0.24.04.2 500
# 500 <http://ports.ubuntu.com/ubuntu-ports> noble-updates/main arm64 Packages
# 100 /var/lib/dpkg/status
# 8.0.39-0ubuntu0.24.04.1 500
# 500 <http://ports.ubuntu.com/ubuntu-ports> noble-security/main arm64 Packages
# 8.0.36-2ubuntu3 500
# 500 <http://ports.ubuntu.com/ubuntu-ports> noble/main arm64 Packages
apt install mysql-server=8.0.39-0ubuntu0.24.04.2
위의 두 mysql 문서를 참조했다.
For other installation methods, you must initialize the data directory manually.
These include installation from generic binary and source distributions on Unix and Unix-like systems,
and installation from a ZIP Archive package on Windows.
만약 바이너리 파일이나 소스 파일 / 윈도우는 ZIP 으로 다운받았으면 Data Directory 설정을 따로 해주어야 한다고 한다.
MySQL 셋팅
mysqld
mysqld 는 MySQL Server 로, 싱글 멀티스레드 프로그램 이다. 추가적인 프로세스를 만들지 않는 멀티스레드 프로그램이라는 의미이다.
아마 다른 프로세스의 작명도 그러하듯이, mysqld 는 mysql daemon 이라는 의미일것이다. daemon 의 의미는 백그라운드에서 실행되는 프로세스를 의미한다.
mysqld(MySQL Server)는 데이터베이스와 테이블을 관리하는 MySQL data directory 에 접근하는 것을 담당한다. MySQL data directory 는 로그나 status file 같은 정보들이 저장되는 default location 이기도 하다.
mysqld(MySQL Server)는 클라이언트 프로그램으로부터의 네트워크 커넥션을 listen 하고 있다가 클라이언트를 대신해서 데이터베이스에 접근한다.
mysqld 는 운영체제에 따라 이름이 mysql 인 경우도 있다.
mysqld_safe
mysqld_safe is the recommended way to start a mysqld server on Unix. mysqld_safe adds some safety features such as restarting the server when an error occurs and logging runtime information to an error log. A description of error logging is given later in this section.
mysqld_safe 를 통해서 mysqld server 를 실행할 수 있지만 ubuntu 24.04 버전에서는 systemd 에 의해 mysqld 가 관리되므로 굳이 사용할 필요가 없다. 어떤 역할을 해주는지만 알고 넘어가면 될 것 같다.
- ‘systemd 로 mysqld managing’
Managing MySQL Server with systemd
사실 apt 로 설치하면서 굳이 건들지 않아도 잘 실행되긴 한다. 그래도 추가적인 설정에 대해 궁금하면 읽어봐야 할 것 같다.
ubuntu 24.04 기준으로 systemctl 은 mysqld 실행 파일에 대한 서비스 이름을 ‘mysql’ 로 지정한다고 한다.
따라서 mysqld 가 잘 실행되었는지는 systemctl status mysql 으로 확인할 수 있고 실행시키려면 systemctl start mysql 로 할 수 있다.
초기 MySQL 계정 셋팅
Securing the Initial MySQL Account
초기 root 계정은 비밀번호를 가지고 있을 수도 있고, 아닐 수도 있다. 나의 경우에는 비밀번호가 없었는데 비밀번호가 있다면 위의 문서를 참고하면 될 것 같다.
비밀번호가 없을 경우에는 root 계정으로 들어가서 비밀번호를 설정하라고 한다.
shell
# mysql 로그인 전이므로 로그인해준다.
$> mysql -u root --skip-password
# mysql 로그인 후, mysql 프롬프트 내부
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'password-you-want';
# 이후 로그인 하려면
$> mysql -u root -p
Enter password: (enter root password here)
가상머신에 mysql 을 설치하고, 외부에서 이 mysql 에 접근하는 방법이 tcp/ip 를 기준으로 2가지인데
하나는 직접 host:port 로 접근하는 것이고 두 번째로는 ssh 를 통해서 해당 host 에 접속해서 mysql 에 접근하는 것이다.
ssh 로 접근하게 되면 ssh 연결 자체가 암호화되기 때문에 안전하다는 장점이 있으나 데이터 전송 성능이 떨어진다.
직접 tcp 로 접근하게 되면 보안은 좀 떨어지지만 속도가 빠르다.
또한 직접 tcp로 접근하게 되면 mysql 에서 IP 를 허용해주어야 한다.
우선 hoeh 라는 새로운 계정을 만들어서 권한과 허용되는 IP대역을 부여해보자.
shell
# root 계정으로 로그인
mysql -u root -p
mysql> use mysql
# hoeh@'모든 ip 대역' => 'hoeh'@'%'
mysql> CREATE USER 'hoeh'@'%' identified by 'password-you-want';
# Query OK, 0 rows affected(0.00sec)
# 모든 권한 부여
mysql> GRANT ALL PRIVILEGES ON *.* to 'hoeh'@'%';
# 권한 새로 고침
mysql> flush privileges
타입 스크립트, MySQL2 Import 문제 해결
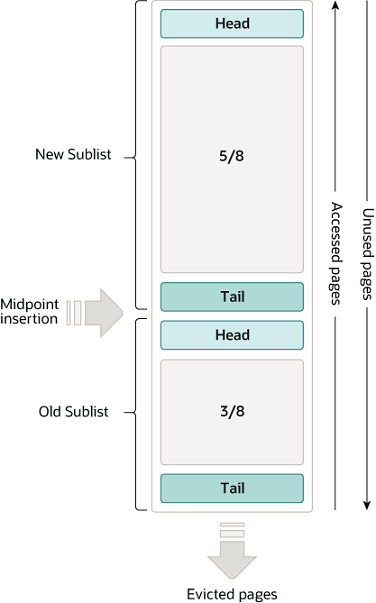 image.png
image.png
import mysql from 'mysql2/promise 를 입력하니까 위 사진과 같은 오류가 발생했다.
분명 npm 으로 mysql2 도 설치를 했고 node_module 파일과 package.json 에도 mysql2 가 있는 것을 확인했는데도 해당 오류가 사라지지 않았다.
심지어 일단 실행을 시켜보니까 정상적으로 동작하기는 했다.
그래서 일단 어떤 오류인지 찾아보았다.
아키텍처
[10분 테코톡] 우디의 Flux Architecture
MVC 의 단점
MVC 패턴을 사용하게 되면 프로젝트의 규모가 커짐에 따라 복잡성이 너무 커지게 되었는데, 여러 컨트롤러들이 여러 개의 뷰를 참조하는 등의 거미줄 같이 얽히게 되기 때문이다.
게다가 프론트엔드에 MVC 패턴을 그대로 가져다 쓰기는 살짝 애매했는데 보통 MVC 에서 View 는 그냥 만들어지는 결과물에 불과하다. 컨트롤러가 입력을 받고, 모델에서 데이터를 가져와서 만드는 그런 결과에 불과하다.
그런데 프론트엔드에서의 view 는 단순한 결과물이라고 하기엔 조금 다르다.
프론트엔드의 view 는 수 많은 이벤트들이 발생을 하는, 뷰가 마치 컨트롤러처림 역할을 수행해야 하는 일이 발생한다.
-> 서버에서 html 을 전부 렌더링해서 주는 상황이라면 조금 다를 수 있을 것 같기도하고..
-> 이 경우에서는 서버에서 MVC 를 쓰기에 아주 적절해보이긴 한다.
게다가 프론트엔드에는 뷰가 매우 다양할 수 있고 모델도 마찬가지로 매우 많을 수 있다. 따라서 뷰와 모델간 복잡도가 매우 올라간다.
이를 해결하기 위해 MVC 패턴의 컨트롤러를 돌고오게 되면 컨트롤러에는 수 많은 비즈니스 로직이 들어가게 되고 컨트롤러의 복잡성이 너무 커지게 된다.
프론트엔드에서의 View 는 계층적인 구조를 가지는 것이 필요하다. 그도 그럴 것이 DOM 조작을 통해 View 를 계속 수정해나갈텐데 DOM 자체가 트리, 즉 계층 구조를 가지고 있다.
사용자의 요청이나 서버의 요청 혹은 SetTimeout 같은 타이머 등의 요청으로 View 는 재랜더링 되는 경우가 굉장히 많고 이렇게 View 를 제어하기 위해서는 계층 구조(DOM 구조) 를 활용하면서 재랜더링 하는 View 를 최소화해야한다.
-> 서버 사이드의 문제점?
렌더링, 즉 DOM 을 조작하는 것은 프론트엔드에 있어서 가장 비싼 비용, 가장 느린 작업이다.
 image.png
image.png
 image.png
image.png
과연 이러한 문제들을 MVC 가 잘 해결 할 수 있을까?
이 문제를 해결하기 위해 MVC 를 억지로 끼워넣을 필요는 없다.
그래서 프론트엔드에서 실제로 자주 사용되는 기술들은
- 데이터 바인딩
- MVVM
- Flux
정도라고 한다.
데이터 바인딩
데이터 바인딩은 상태 값과 그 값을 제어하는 요소와의 결합을 의미한다.
대표적으로 svelte 프레임워크에서 사용하는듯 한데, 양방향 바인딩을 이용해서 동시에 값이 변경되게 처리되도록 할 수도 있다.
Model 의 값이 변경되면 View 를 재랜더링 할 수도 있고 (단방향)
여기에 더해서 양방향 바인딩을 하면 View 요소의 변경을 감지해서 Model 을 업데이트 할 수도 있다.
svelte 에서는 내부적으로 eventListener 를 생성해서 양방향 바인딩(two-way data binding)을 한다고 한다.
MVVM
위에서 말한 bind 를 만들어주는 역할을 하는것이 MVVM 에서는 VM 이다.
VM은 뷰에서 쓰는 모델을 가지고 있다가,
뷰에서 변경사항이 생기면 뷰모델이 바뀌고, 뷰모델이 바뀌면 뷰를 재랜더링하는 방식이다.
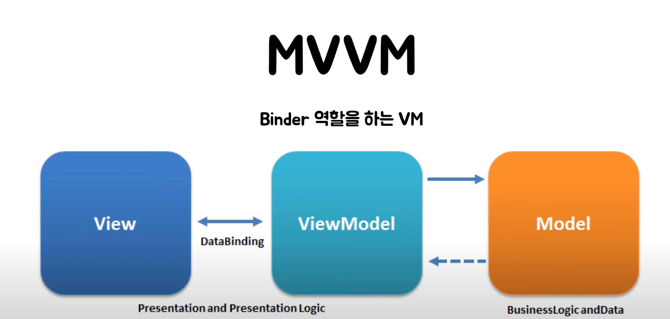 image.png
image.png
Flux
단방향 데이터 흐름을 통해 보다 예측가능하게 상태를 관리할 수 있는 클라이언트 사이드 웹 어플리케이션 아키텍쳐
Flux 는 기본적으로 한 방향으로 흐름을 진행하려고 한다.
계층적인 구조를 가지는 뷰가, 모델과 서로 지속적으로 호출을 하면서 의존성과 복잡성이 올라가게 되는데 이 흐름을 쉽게 만들기 위해서
한 방향으로 만들려는 시도이다.
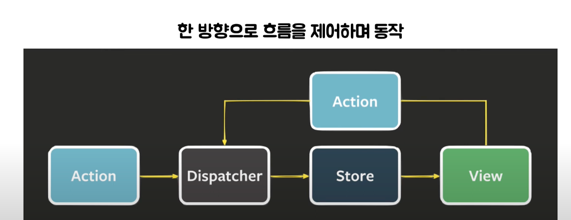 image.png
image.png
Action
맨 왼쪽의 Action 은 사용자가 view 와 상호작용하면서 일어날 수도 있고, 타이머함수에 의해서 생길 수도 있고 서버에서 데이터를 받을 수도 있다.
Dispatcher
Action 은 그저 액션에 대한 정보를 담고 있는(ex. 액션 이름, 내용 등) JSON 같은 객체일 것이다.
따라서 정보를 가지고, 상태 저장소(store) 에 적절히 잘 전달해줄 객체인 Dispatcher 가 필요하다.
Store
Store 는 어플리케이션의 상태가 저장되어 있는 전역 상태 저장소로 Dispatcher 에 의해 넘어온 액션을 통해서’만’ 값이 수정된다.
Store 는 스스로 상태를 변경하는 로직을 가지고 있기 때문에 Action 이나, Dispatcher 에 의해 변경 로직이 실행되는 것이 아니라 스스로 가지고 있는 변경 로직을 실행하는 것이다.
Store 는 어떠한 상태라도 저장할 수 있는 전역 상태 저장소로, 상태가 변경되면 View 에게 통지하게 된다. (event Emit)
View
View 는 관심 있는(구독 하고 있는) ‘어플리케이션의 상태’ 가 변경될 때마다 재렌더링 되는 컴포넌트다.
View 또한 재랜더링 하는 로직을 스스로 가지고 있고 store 가 변경됨에 따라 하위 컴포넌트에게 변경된 상태를 전달하기도 하므로, MVC 패턴 관점으로는 controller 의 역할도 겸한다고 볼 수 있다. 그래서 Controller-View 라고 불리기도 한다.
View 에서 발생한 Action 은 다시 Dispatcher 에게 전달된다.
프론트엔드에는 규모가 커지면서 복잡한 View 들도 많이 등장했는데
이러한 문제점을 해결하고자 MVVM 패턴이 등장하게 되었다.
Flux 아키텍쳐
왜 Flux 를 선택했나
클라이언트 사이드 패턴을 공부해보면서, MVC 패턴을 그대로 사용하기 보다는 flux 패턴을 사용해보고 싶어서 학습 위주로 진행을 했습니다.
우선 MVC 패턴을 그대로 가져다 쓰기는 힘들다는 이야기를 듣고 조금 더 찾아보았습니다. MVC 패턴은 검색해보면 나오는 이미지가 다 다를 정도로 마치 코에 걸면 코걸이, 귀에 걸면 귀걸이인 것 처럼 MVC 패턴을 쓰기 위해 코드를 욱여넣는 것이 올바른 방법이 맞나? 라는 생각이 들었습니다.
그래서 MVVM, flux, 데이터 바인딩 등의 다양한 아키텍처를 찾아보고 어떤 방식이 좋을지를 고민해보는게 이번 주 학습의 첫 시작이였습니다.
데이터 흐름을 단방향으로 가져가는 것이 일반적이다. 라는 이야기를 듣기도 했고, 이번 주 스터디그룹에서 이야기가 나왔던 flux 패턴이 가장 흥미로워보였습니다.
그런데 제가 React 나 Redux 등 프론트엔드에 정말 무지해서 학습하는데 시간이 오래 걸릴 것 같아 이걸 학습하고 적용시켜보는게 맞는지 고민이 되었지만, 네부캠이 아니면 이런 기회가 없다고 생각해서 도전해보게 되었습니다.
여러가지 flux 자료들을 찾으면서 가장 많이 활용한 자료는 facebook-flux 이었는데 flux 자체가 페이스북에서 먼저 제안한 방식이기 때문에 해당 레포지토리의 소스를 한 번 읽어봐야겠다 라는 생각으로 읽어보았습니다.
다만 제가 참고한 facebook-flux 의 아이디어가 실제로 나온지는 9년이 넘은 것 같고 위의 레포는 아카이브에 들어가있는, 지금은 업데이트가 되지 않는 레포입니다. 아마 더 최신의 버전이 react 나 redux 등에 있지 않을까 싶습니다. 그래서 앞으로 설명드릴 내용은 위의 facebook-flux 레포를 기준이라는 것을 미리 말씀드리고 싶습니다.
또한 프론트 문외한이 이해한 내용이라 틀린 내용이 있을 수 있습니다
참고 자료
Flux
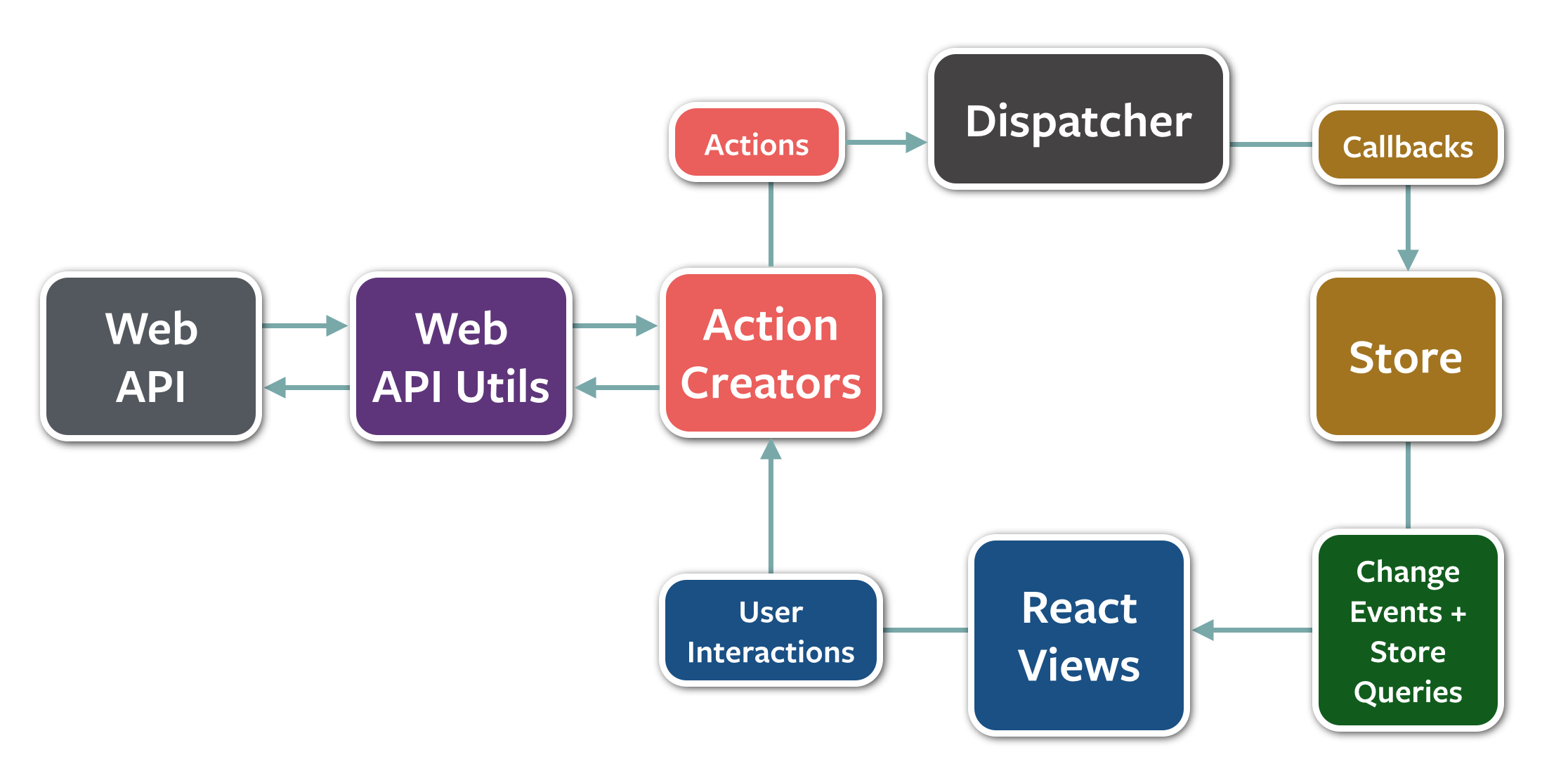 image.png
image.png
flux 패턴의 핵심은 위의 그림에서와 같이 단방향의 데이터 흐름 입니다.
위의 그림에서 가장 눈에 띄는 요소는 Dispatcher , Store, View 입니다.
데이터의 흐름을 살펴보면 화살표가 시계방향으로만 이어져있을 뿐, 흐름이 역행하거나 단계를 건너뛰고 진행되는 일이 없습니다. 이러한 단순한 흐름 덕분에 코드의 흐름 자체를 이해하기가 쉬워지고 가독성을 얻을 수 있습니다.
데이터 흐름
그렇다면 어떻게 이런 단방향의 흐름을 설계했을까요?
flux 에서는 모든 Action(사용자의 인터랙션, 타이머 함수의 실행, 서버로부터 데이터 받기 등)은 Dispatcher 라는 마치 중앙집중허브에 전달됩니다. Dispatcher 는 이런 Action 들을 모든 Store 에게 전달을 해주고, Store 는 Action 을 기준으로 자신의 상태값을 갱신합니다. 그리고 갱신이 완료되면 ‘change’ 라는 이벤트를 emit 함으로써 View 가 새로운 상태값을 가지도록 만듭니다.
여기서 단방향의 흐름을 위해 Store 는 callback 함수를 Dispatcher 에 등록을 하게 되는데, callback 함수에는 Store 자신의 메소드를 적절히 잘 활용해서 상태값을 바꾸는 등의 역할을 수행합니다.
또한 Store 는 eventEmitter 를 활용해서 상태값이 갱신되면 ‘change’ 라는 이벤트를 emit 합니다. 이 emit 을 통해 View 는 상태값이 바뀌었음을 알게 되고 Store 에게 새로운 상태값을 받아와 재렌더링을 합니다.
Dispatcher
페이스북은 여기서 Dispatcher 의 역할이 pub-sub 구조와는 조금 다르다고 이야기 합니다.
Dispatcher는 등록된 callback에 데이터를 중계할 때 사용된다. 일반적인 pub-sub 시스템과는 다음 두 항목이 다르다:
- 콜백은 이벤트를 개별적으로 구독하지 않는다. 모든 데이터 변동은 등록된 모든 콜백에 전달된다.
- 콜백이 실행될 때 콜백의 전체나 일부를 중단할 수 있다.
첫 번째로 Store 의 콜백은 이벤트를 개별적으로 구독하지 않습니다. 즉 Dispatcher 에 들어오는 Action은 특정 Store 에게만 전달되는 것이 아니라 모든 Store 에게 전달됩니다. Store 는 Action 의 type 을 기준으로 자신이 필요로하는 Action 인지를 구별하여 작업을 진행합니다.
이러한 과정은 오버헤드를 불러올 것이라고 생각되는데, 그럼에도 이러한 방식을 선택한 이유를 생각해보자면 흐름과 로직을 단순화 할 수 있다는 것이라고 생각합니다.
두 번쨰로는 콜백이 실행될 때 다른 콜백들을 중단(지연)시킬 수 있다는 것입니다. 이는 콜백 간의 순서를 보장할 수 있다는 이야기인데 facebook 에서 들었던 예시로 살펴보겠습니다.
javascript
const flightDispatcher = new Dispatcher();
// 어떤 국가를 선택했는지 계속 추적한다
const CountryStore = {country: null};
// 어느 도시를 선택했는지 계속 추적한다
const CityStore = {city: null};
// 선택된 도시의 기본 항공료를 계속 추적한다
const FlightPriceStore = {price: null};
위의 예시는 항공편 예약 서비스로, 나라를 선택하고 해당 나라의 도시를 선택하고, 그 도시의 기본 항공료를 추적하는 시스템이라고 보면 될 것 같습니다. 사용자가 새로운 나라와 새로운 도시를 선택했다면 ‘새로운 나라 선택 callback’ 이후에 ‘새로운 도시 선택 callback’ 이 진행되어야 하는, 일련의 순서가 존재하게 됩니다. 따라서 flux 에는 waitFor 이라는 메소드로 이를 구현했습니다.
다만 이번 TodoApp 에 있어서 waitFor 이 필요하지는 않다고 생각해서 실제로 미션을 위한 flux 를 설계할때는 waitFor 을 고려하지 않았습니다.
Store
Store 는 도메인별로 상태를 관리합니다. Store 는 자신의 callback 을 dispatcher 에 등록합니다. callback 은 action 을 파라미터로 받아서, switch 문을 활용하여 action 의 type 을 기준으로 여러 작업을 수행합니다.
facebook 에서는 이 switch 문을 포함하고 있는 함수를 reduce 라고 이름 지은 것 같습니다. 따라서 저도 Store 라는 클래스에 reduce 라는 추상 메소드를 선언하고 CardStore, ColumnStore 등이 이 reduce 함수를 구현하도록 진행했습니다.
javascript
export default abstract class Store<TState> extends EventEmitter {
private readonly dispatcher = dispatcher;
protected state: TState;
protected constructor(state: TState) {
super();
this.state = state;
// this.setState(state);
}
...
abstract reduce(action: Action): void;
}
Store 는 아래와 같은 특징이 있습니다.
- Cache data (데이터를 캐싱해둔다)
- Expose public getters to access data (never have public setters) (데이터에 접근하기 위한 Getter 를 노출시키지만, Setter 는 절대로 있어선 안된다)
- Respond to specific actions from the dispatcher (디스패처로부터 넘어온 특정 액션(관심있는 액션)에 응답한다)
- Always emit a change when their data changes (데이터의 변화가 있을 때 항상 ‘change’ 이벤트를 emit 한다)
- Only emit changes during a dispatch (디스패치 중에만 ‘change’ 이벤트를 emit 해야한다.)
이중에서 마지막 Only emit changes during a dispatch 가 살짝 의아할 수 있습니다.
dispatch 중이라는 것은, 디스패쳐로부터 데이터가 넘어왔을 때를 의미합니다. 그때 적절한 함수를 통해서 데이터를 변경하고 ‘change’ 이벤트를 emit 할텐데 이 과정 말고 다른 추가적으로 ‘change’ 이벤트를 emit 하는 일이 없어야한다는 의미입니다.
이는 데이터 흐름의 일관성과 예측 가능성을 유지하고 비동기 작업이나 외부 이벤트로 인한 예기치 않은 상태 변경을 방지하기 위함입니다.
View
마지막으로 가장 고민이 되는 View 인데 facebook flux 에서는 React 를 활용하여 View 를 만들고 재렌더링 하는 방법을 사용하고 있었습니다. 저는 react 를 잘 모르기도 하고 이번 미션에서 사용할 것도 아니였기 때문에 내부 동작을 비슷하게 가져와서 구현을 할 생각입니다. facebook-flux 에서도 Store 가 eventEmitter 를 활용하여 이벤트를 emit 하는것으로 보여서 비슷한 방식으로 View 에게 이벤트를 전달할 생각입니다.
별거 없는 코드지만 mini-flux 에 flux 동작을 조금 따라해보는 코드를 올렸습니다.
스프린트 3주차 학습정리 (Merge, Squash Merge, 타입스크립트 유틸리티 타입)
Merge 전략
이번에 프로젝트를 진행하면서, upstream 레포지토리를 fork 해와서 새로운 Feature 브랜치를 생성해서 작업을 했다.
merge 가 되는 순서를 간략히 설명하면, Feature(기능 개발 브랜치) -> downstream 개인 브랜치 -> upstream 개인 브랜치 순서로 병합이 된다.
여기서 downstream 개인 브랜치 -> upstream 개인 브랜치 과정의 병합은 내가 하는 것이 아니라, 관리자 혹은 Github Action 봇이 하게 된다.
처음에는 아무 생각 없이 PR 을 올려두고 병합이 되기 전까지 계속 Feature 브랜치에서 작업을 했다. 그러고 나서 PR이 병합될 때 문제없이 잘 병합되길래 앞으로도 문제가 생기지 않을 줄 알았다.
그러다가 여느 날과 마친가지로 PR 을 올려두고 Feature 브랜치에서 계속 작업을 하다가 병합이 된 후에, 추가로 작업한 내용을 upstream 개인 브랜치로 올리려고 했더니 충돌이 발생했다. 분명 이전과 별 다를 것 없이 머지되었다고 생각했는데 왜 이번에는 충돌이 나는걸까? 에 대해 궁금증이 생겼고, 같은 팀 동료분께서 해답을 찾아 주셨다.
깃의 merge 에 대해서는 git merge 와 git rebase 에 대해서 이전에 작성을 했었는데, 여기서 작성하지 않았던 merge 가 하나 있다.
깃의 Merge 에는 일반 Merge, rebase, 그리고 squash merge 가 있다. 위의 학습 정리에서는 Merge 와 rebase 의 차이점을 중심으로 살펴봤었는데, 이번에는 일반 Merge 와 Squash merge 에 대해 살펴보려고 한다.
Merge 와 Squash Merge
Merge 는 기본적으로 Commit 이 몇 개가 쌓여있든 간에 그대로 병합시킨다. 다시 말해서 누적되어 있는 commit 이 그대로 들어와서 병합된다.
그렇기 때문에 커밋의 숫자가 많은 경우에는 커밋을 하나씩 읽고 흐름을 이해하는데 다소 힘들 수 있다.
반면에 Squash Merge 는 몇 개의 Commit 이 쌓여있든 간에 새로운 하나의 커밋으로 만들어서 병합된다.
여기서 새로운 하나의 커밋으로 만든다는 것이 중요하다.
1,2,3 Commit 에 해당하는 PR 을 올려두고, 계속 작업을 진행하면서 4,5,6 Commit 을 만들었다고 하자.
여기서 일반 머지를 하게 되면 1,2,3 커밋이 그대로 들어가면서 Commit 4 는 3을 기준으로 만들어진 커밋이기 때문에 커밋에 충돌이 생기지 않는다.
그러나 스쿼시 머지를 하게 되면 1,2,3 커밋이 하나로 합쳐져서 새로운 커밋(예를 들어 Commit 10)을 만들게 된다.
하지만 Git 은 Commit 1,2,3 이 하나로 합쳐진게 Commit 10이란걸 알지 못한다. 이렇게 되면 Git 은 Commit-4 와 Commit-10을 보고는 코드를 비교해보고 충돌이 일어난다면 이때는 conflict 를 발생시킨다. (물론 Commit 10 과 Commit 4 간의 코드 충돌이 없다면 스쿼시 머지임에도 충돌이 나지 않을 것이다.)
Typescript 유틸리티 타입
이번에 타입스크립트로 코드를 작성해보면서 필요한 interface 들을 미리 정의해놓고 사용을 했다.
Partial
이렇게 선언한 Card 라는 타입은 title, content, id 라는 속성을 무조건 가져야한다.
이제 카드에 대한 수정 기능을 추가하면서 Card 타입의 일부분(title, content, id) 중에서 최소 1개, 최대 3개 전부 다 골라야 하는 상황이 생겼다.
수정을 한다고 하면 title 만 바꾸고 싶을 수도 있고, 전부 다 바꿀 수도 있기 때문이다.
이럴 때는 Partial 을 사용하면 된다. Partial<Card> 라는 뜻은 속성을 가질수도 있고 가지지 않을 수도 있다(옵셔널)는 뜻이다.
typescript
interface Card {
title: string;
content: string;
id: string;
}
const partialCard_1 : Partial<Card> = { title : 'title'} // OK
const partialCard_2 : Partial<Card> = { title : 'title', id : 'id'} // OK
const partialCard_3 : Partial<Card> = { } // OK
Required
만약 속성들 ‘모두’가 필수적인 속성이 되기를 원한다면 Required 를 사용하면 된다.
예를 들어
typescript
interface Card {
title: string;
content: string;
id?: string;
}
// id 는 옵셔널이다!
const partialCard: Partial<Card> = { title: "this-is-title", content: 'this-is-content' }; // OK
// id 가 없어서 안된다.
const requiredPerson: Required<Person> = { title: "this-is-title", content: "this-is-content" };
Pick
그렇다면 이번에는 Card 의 속성을 콕 찝어서 선언하고 싶다면 어떻게 할까?
이럴 때는 Pick 을 사용하면 된다. Pick<Card, 'title' | 'content'> 은 Card 타입 중에서 title 과 content 를 콕 찝은 타입이다.
typescript
interface Card {
title: string;
content: string;
id: string;
}
// content 필요
const pickCard_1: Pick<Card, 'title' | 'content'> = { title: "this-is-title" };
// id 는 있을 수 없다.
const pickCard_2: Pick<Card, 'title' | 'content'> = { title: "this-is-title", id: "my-id" };
스프린트 4주차 학습정리(Virtual DOM 과 재렌더링)
재렌더링 방식
바닐라 JS 로 flux 패턴과 Component 를 잘게 쪼개서 부모 컴포넌트에서 자식 컴포넌트로 props 를 전달하는 과정을 흉내내보면서 재렌더링 에 대한 고민이 생겼다.
DOM 이 렌더링 되는 과정은 여기서 간단하게 볼 수 있다. DOM 렌더링
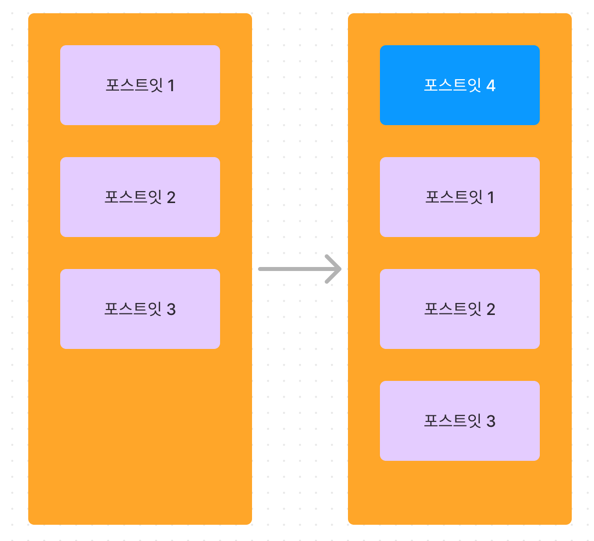 image.png
image.png
위와 같이 포스트잇 1,2,3 이 있던 상황에서 맨 위에 포스트잇 4가 들어오게 된다면, 어떻게 해서 재렌더링을 최소화 시킬 수 있을까?
여기서 가장 좋은 방법은 역시 포스트잇 4 만 추가하고 포스트잇 1,2,3 에 미치는 영향은 최소화 시키는 방법일 것이다.
우선 상황을 보면 포스트잇 4 가 맨 위에 추가되면서 포스트잇 1,2,3 은 화면 상 위치 가 바뀌었다. 물론 1,2,3 간의 순서가 바뀌지는 않았지만 한 칸 씩 내려앉게 되었다.
이런 경우에는 DOM 에서 layout 을 잡는 작업인 reflow 와 화면에 그리는 작업인 reflow 과정이 포스트잇 4 에 일어난다.
그리고 이 reflow, repaint 작업은 DOM 조작 중에서 가장 비싼 작업들이다.
그렇다면 포스트잇 1,2,3 은 어떻게 될까? 아쉽지만 포스트잇 1,2,3 간에는 순서가 바뀐 것이 없음에도 reflow 가 발생한다. 포스트잇 1,2,3 의 위치가 바뀌었기 때문이다.
어떻게 해도 포스트잇 1,2,3 의 위치가 바뀌었기 때문에 브라우저에서 reflow 가 일어나야만 한다. 이렇게 하나의 카드만 새로 추가 되는 경우에는
insertBefore 메소드를 사용해서 그냥 끼워넣어도 성능에 큰 차이가 없을 수’도’ 있다.
다만 아래 처럼 여러 개의 카드가 동시에 추가 되는 경우를 한 번 생각해보자.
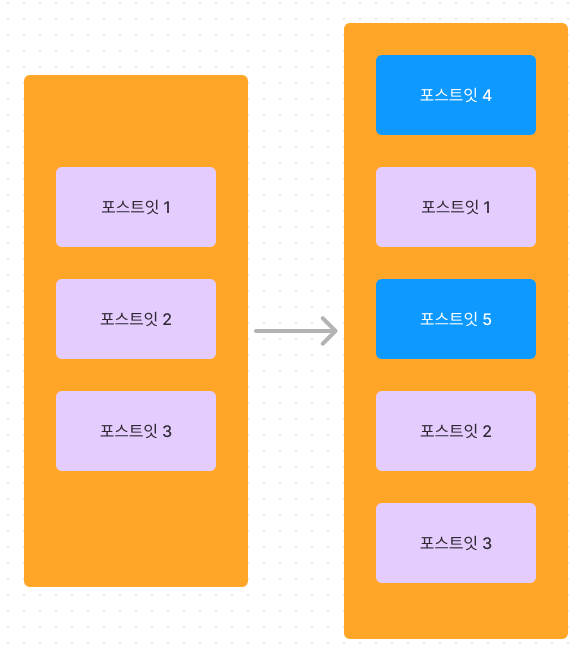 image.png
image.png
이 경우에 가장 쉽게 이 로직을 작성해보면
javascript
// 새로운 카드들이 들어있는 배열
newCards.forEach((newCard)=>{
...
column.insertBefore(newCard, ...);
...
})
이렇게 newCards 배열을 순회하면서 포스트잇 4를 추가하고, 그 뒤에 포스트잇 5까지 추가하는 로직이면 상당히 간단하게 구현할 수 있을 것 같다.
하지만 이런 방식은 정말 비효율적인 방식이다. 위에서 고민했던 것을 다시 생각해보면 DOM 에 비효율적인 reflow repaint 가 일어나는 것을 알 수 있다.
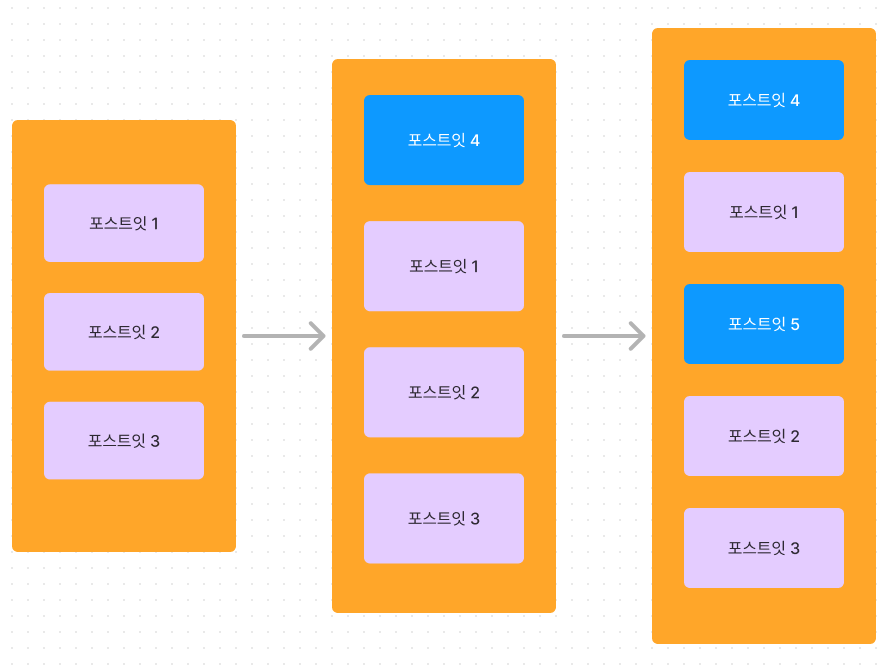 image.png
image.png
insertBefore 메소드는 실제로 DOM 의 재렌더링을 유발한다. 정확히 말하면 DOM 에 새로운 요소가 업데이트(insertBefore 가 요소를 업데이트) 될 때마다 재렌더링이 발생한다. 즉 한 번의 insertBefore 마다 한 번의 DOM 재렌더링이 발생한다.
실제로 카드를 2개를 동시에 추가하는 것 처럼 보일 수 있으나 이미지처럼 추가되는 카드의 수 만큼 insertBefore 가 발생하고, 그 만큼 reflow repaint 가 발생할 수 있다.
이렇게 비효율적으로 여러 번 발생하는 reflow repaint 를 최소화시키는 것이 이번 고민의 핵심이었다.
Virtual DOM
그렇다면 어떻게 reflow repaint 를 최소화할 수 있을까? 이 고민은 완벽하게 해결하려면 상당히 복잡할 거라고 생각한다.
실제로 카드 하나만 추가할 때는 insertBefore 한 번 하는 것이 더 나은 경우일 수 도 있는 것처럼 경우에 따라서 최선의 해결책이 달라질 수 있기 때문이다.
그렇다면 React 는 어떤 방식으로 재렌더링을 효율적으로 하고 있을까?
리액트는 Virtual DOM 과 Diff 알고리즘을 핵심으로 사용하고 있다.
Vanilla Javascript 로 가상돔 만들기 를 참고하면 더욱 더 이해가 빠를 것 같다.
브라우저가 HTML 을 파싱해서 만든 결과인 DOM 트리는 DOM 요소가 업데이트 될 때마다 (위에서 insertBefore 등으로 요소를 업데이트하는 등) 재렌더링 작업을 거치게 되고
이때 reflow repaint 가 발생한다. 따라서 우리는 DOM 요소가 업데이트가 되어도 바로 재렌더링을 하는게 아니라 업데이트 되는 요소들을 모아서 재렌더링 해야한다.
그러기 위해서는 브라우저가 만드는 진짜 DOM 을 가지고는 할 수 없다. 따라서 우리는 DOM 과 매우 유사한 Virtual DOM 을 만들어서, Virtual DOM 에 변경사항을 전부 업데이트하고 해당 부분만 Virtual DOM 으로 patch 할 것이다.
우리가 만든 카드 웹에서는 포스트잇 1,2,3 말고 더 많은 요소들이 DOM 에 존재할 것이다. 그렇지만 우리가 바꾸고 싶은 부분인 포스트잇 컬럼 부분만 보면 충분하기 때문에 Real DOM 전체를 본따서 만드는 것이 아니라 포스트잇 컬럼 부분의 DOM 만 본따서 Virtual DOM 을 만들면 된다.
이후에 Diffing(비교) 알고리즘으로 변경된 포스트잇들을 업데이트하고 Real DOM 에서 Virtual DOM 에 해당하는 부분을 patch 하면 된다.
위의 블로그에서는 Real DOM 을 메모리에만 올려서 활용하는 방식으로 Virtual DOM 을 생성한다고 보면 될 것 같다.
그리고 비슷하게 메모리에만 올려서 활용할 수 있는 DocumentFragment 를 활용해도 좋을 것 같다.
DocumentFragment 도 DOM 의 가벼운 버전으로, DocumentFragment 에 요소들이 업데이트 되어도 재렌더링이 되지 않는다.
Diff 알고리즘
- 원래 있던 카드가 없다 -> 삭제
- 원래 없던 카드가 있다 -> 추가
- 원래 있던 카드의 내용이 바뀌었다 -> 변경
여기서 3번의 경우는 살짝 복잡할 수 있다. 내용이 바뀌었는가? 를 비교하는 로직이 필요하기 때문이다.
만약 카드 객체가 단순히 String 타입이라면? 문자열만 비교해보고 바뀌었는지 아닌지를 구분할 수 있다.
그러나 카드 객체는 보통 여러 자식을 가지고 있는 태그일 것이므로, 모든 자식 태그들을 비교해서 같은지 같지 않은지 확인해야한다.
스프린트 5주차 학습정리(환경변수)
환경변수
리눅스를 다뤄볼때면 늘 나오는 키워드인 export, source, . 까지 완벽하게 이해하고 사용하지는 못했던 것 같다.
이번 기회에 확실하게 짚고 넘어가보자
우선 환경변수 라는 말은 무엇일까?
환경 변수(Environment Variables) 는 시스템의 전역 설정 으로 프로그램이나 명령어가 실행될 때 참고하는 설정 정보를 담고 있는 변수이다.
그런데 조금 아래에서 보겠지만 전역 설정이라는 것 치고는 전역이 아닌 것 같은 일이 발생한다.
export
Export 키워드는 현재 셸에서 환경 변수에 등록하는 키워드이다. 아래의 경우 NAME 이라는 변수에는 hoeh 값이 들어있다.
shell
# nameScript.sh
...
export NAME=hoeh
echo $NAME
...
$ ./nameScript.sh
# hoeh
$ echo $NAME
# hoeh 가 출력될까?
우선 nameScript 라는 스크립트 파일에 export NAME=hoeh 라고 작성한 뒤에 echo 명렁어로 NAME 을 출력하는 스크립트를 작성해보자.
이후에 nameScript 를 실행해보면 hoeh 라는 문자열이 잘 출력된다. 이는 NAME 이라는 환경변수에 hoeh 라는 값이 잘 들어가있음을 알려준다.
그런데 스크립트 실행 후에 따로 echo $NAME 을 실행해보면 hoeh 가 출력될까?
사실 hoeh 가 아니라 아무것도 출력되지 않는다.
분명 nameScript 를 실행했을때는 echo $NAME 에서 hoeh 가 정상적으로 출력되었는데 왜 echo $NAME 을 따로 실행하니까 출력되지 않는걸까?
이유는 자식 프로세스와 export 의 범위를 알아야한다.
- 쉘 스크립트를 실행하면 현재 프로세스가 아닌 자식 프로세스를 fork 해서, 자식 프로세스에서 nameScript 스크립트가 실행된다.
- export 는 실행된 프로세스와 그 자식 프로세스에게만 전파된다.
이 두 가지의 이유를 조합해보면, nameScript.sh 를 실행할 때 자식 프로세스(B) 를 만들어서 해당 스크립트의 내용이 실행되기 때문에,
B 에서 export 를 실행한 것이 되므로 B 와 B 의 자식들은 NAME 이라는 환경 변수를 사용할 수 있다.
그러나 B 의 부모 프로세스, 즉 우리가 입력하고 있는 프로세스에서는 NAME 이라는 환경 변수가 없다.
그렇다면 자식 프로세스의 환경 변수를 부모 프로세스로 역전파(?) 시키는 방법이 필요할 것 같은데 그런 방법은 따로 없다.
source
그렇다면 자식 프로세스에서 일어난 환경 변수 설정을 부모 프로세스가 알게하는 방법이 있을까?
프로세스는 스레드와 다르게 ‘독립성’ 이 강조된다. 자식 프로세스를 만들 때, 환경 변수를 복사해서 만들기 때문에 자식 프로세스에 영향이 있을 뿐, 부모 프로세스에게 영향을 끼치면 안된다.
따라서 우리는 부모 프로세스가 환경변수 설정을 적용되지 못하게 하는 원인을 제거해버릴 수 있다.
source 명령어는 스크립트 파일을 현재 셸 에서 실행한다. 즉 자식 프로세스를 만들지 않고 부모 프로세스에서 바로 환경 변수를 설정하기 때문에 현재 셸에 환경변수 설정이 적용된다.
스프린트 7주차 학습정리(DB 인덱싱, 로컬 모듈)
Subscribe to hoeeeeeh
Get the latest posts delivered right to your inbox
