네트워크 CS 지식
네트워크 CS 지식 정리
전이중화 통신
- Full Duplex : 양쪽 장치가 동시에 송수신할 수 있는 방식
- 회선이 두 개(송신로, 수신로)가 있어서 같은 시간에 데이터를 주고 받을 수 있는 것이 전이중화 통신
반 이중화 통신은 회선 하나로 보내기 때문에 양방향으로 보내기 전에 먼저 상대방이 보냈는지 확인하는 기술 CSMA-CD
충돌이 발생하면 잠깐 기다렸다가 다시 보내기
무선랜
무선랜은 반이중화 통신을 사용
half duplex (반이중화 통신)은 양쪽 장치가 서로 통신은 할 수 있지만 동시에는 못한다. 즉 한 번에 한 방향만 가능
CSMA/CA
- 사용하지 않는 채널 발견
- IFS 시간만큼 기다림
- 프레임 보내고, 다음 프레임 보내기 전까지 IFS 만큼 기다림
대표적인 예시) 와이파이, 블루투스, 지그비
2.4Ghz : 장애물에 강함, 속도가 느리다, 호환성이 좋다
5Ghz : 장애물에 약함, 속도가 빠르다, 호환성이 비교적 나쁘다
대규모 트래픽으로 인한 서버 과부하 해결 방법
서버 과부하 : 서버가 리소스를 소진하여 들어오는 요청을 처리하지 못할 때. (응답없음)
자원의 한계점 도달
→ 자원을 빠르게 증가시켜주기 (오토 스케일링) 클라우드 와치가 모니터링한다.
→ 무료 모니터링 (netData) 도 있다.
→ 쓰레스 홀드(임계치)를 정해놓고 이상으로 넘어가면 알림을 준다.
모니터링을 하는 이유
모니터링을 통해 어떤 서비스에 트래픽이 몰리는지, 어떤 이유로 몰리는지 분석이 가능하다.
또한 페이지를 나누어 트래픽을 나눌 수도 있다.
로드밸런서
로드밸런서를 통해서 트래픽을 분산
오토 스케일링을 하는 동안 시간이 조금 걸리기 때문에, 로드 밸런스를 앞 단에 두고 트래픽을 분산 시킨다.
로드 밸런서에다가도 오토 스케일링을 걸기도 한다. (트래픽이 많은 기업)
블랙스완 프로토콜
예측할 수 없는 사고가 일어난 것
엄청나게 많은 대비를 해도 서버가 죽을 수도 있다. 서버가 예기치 못한 사태로 죽고나서 분석은 가능하지만 미리 예측하기는 쉽지 않다.
블랙스완을 대비한 규칙이 있으면 좋다.
구글의 경우에는,
- 영향을 받은 시스템과 각 시스템의 상대적 위험 수준을 확인
→ 체계적으로 데이터를 수집하고 원인에 대한 가설을 수립한 후 이를 테스팅
- 잠재적으로 영향을 받을 수 있는 내부의 모든 팀에 연락
- 최대한 빨리 취약점에 영향을 받는 모든 시스템을 업데이트
- 복원계획을 포함한 우리의 대응 과정을 파트너와 고객 등 외부에 전달
서킷 브레이커
서비스 장애를 감지하고 연쇄적으로 생기는 에러를 방지하는 기법
서비스와 서비스 사이에 서킷브레이커 계층을 두고, 미리 설정해놓은 타임아웃 임계값을 넘어가면 서킷브레이커가 그 이후의 추가 호출에 무조건 에러를 반환하게 한다.
다운된 서비스에 무한정 대기하면서 스레드 혹은 리소스를 잡아먹게 되면서 다른 스레드가 차단되는 현상이 발생할 수 있다.
기다린다는 것은 사용자 입장에서 썩 좋은 경험은 아니다.
기다리는것보다 차라리 오류가 생겼다고 말해주는 것이 더 좋은 경험이다.
따라서 빠르게 알려줄 수 있는 서킷 브레이커가 더 좋을 수 있다.
서킷 브레이커의 상태
- closed (정상) : 네트워크 요청의 실패율이 임계치보다 낮음
- 어느정도는 실패할 수 있다. 100퍼센트가 아니라 90퍼이상 성공하면 괜찮다같이 정할 수 있다
- open (에러) : 에러가 임계치 이상의 상태일 때.
- 요청을 서비스로 전송하지 않고 에러를 반환. 이를
fail test라고 한다.
- 요청을 서비스로 전송하지 않고 에러를 반환. 이를
- half open (확인 중) : 오픈 상태에서 일정 타임 아웃으로 설정된 시간이 지나면 장애가 해결되었는지 확인하기 위한 상태. 장애가 풀리면 closed 상태로, 실패하면 다시 open 상태로 전환
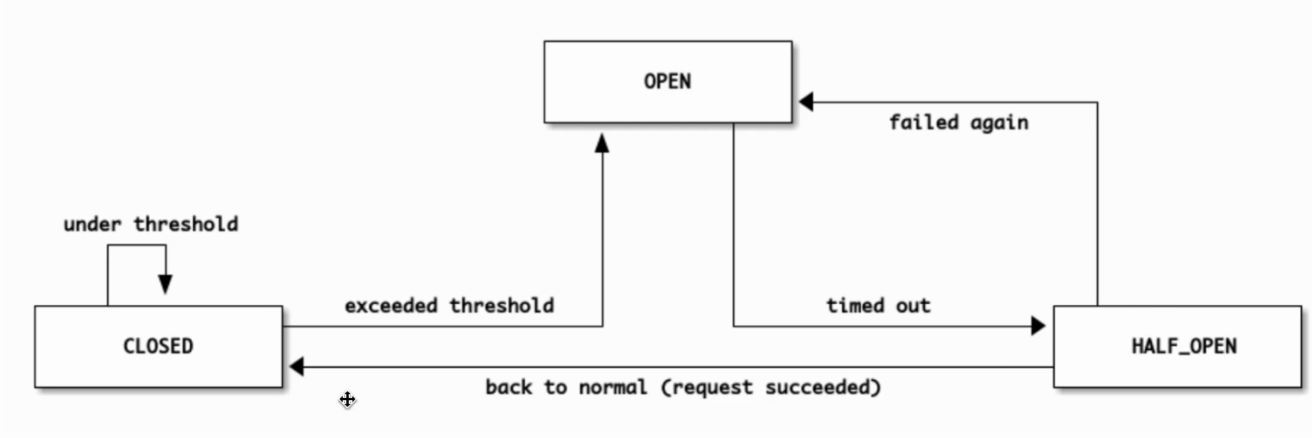 image.png
image.png
서킷 브레이커의 장점
- 연쇄적인 에러 발생을 막아준다
- 일부 서비스가 다운되더라도 다른 서비스를 정상적으로 돌아가게 도와준다.
- 사용자 경험을 높여준다.
Netfilix 의 Hystrix
컨텐츠 관리
어떻게 하면 서버의 부하를 덜 수 있을까
- 불필요한 컨텐츠 제거
- 인프런에서 할인 이벤트를 열었는데 장애가 발생.
- https://tech.inflab.com/202201-event-postmortem/
- 강의 본문을 조회하는 쿼리가
select *로 되어 있어서 사용 여부와 관계 없이 모든 컬럼을 조회
- CDN 을 통한 컨텐츠 제공
- 정적 자원들은 메인 서버가 주는게 아니라, CDN 을 통해서 주면 부하가 분산된다.
- 컨텐츠 캐싱
- 요청 자체를 줄일 수 있다.
- 컨텐츠 압축
- 텍스트 기반 리소스는 gzip / brotli 등을 통해 압축 (70퍼정도로 압축됨)
- 압축 푸는 서버의 자원도 필요
- 컨텐츠의 우아한 저하 (미리 준비된 응답)
- 시스템의 과도한 부하를 줄이기 위해 제공하는 컨텐츠 및 기능을 일시적으로 줄이는 전략 예를 들어 정적 텍스트 페이지를 제공하거나, 검색을 비활성화하거나 더 적은 수의 검색 결과를 반환하거나, 필수적이지 않은 기능을 비활성화
- 이미지나 썸네일 등을 빼버리고 텍스트 기반으로 축소 서빙 (중요한 텍스트만 남기고 제거)
REST API 란 무엇인가요?
→ Restful 한 API
- Uniform-Interface
- API에서 자원들은 각각의 독립적인 인터페이스를 가지며, 각각의 자원들이 url 자원식별, 표현을 통한 자원조작, Self-descriptive message, HATEOAS 구조를 가지는 것을 말합니다.
- 독립적인 인터페이스라는 것은 서로 종속적이지 않은 인터페이스를 말합니다. 예를 들어, 웹페이지를 변경했다고 웹 브라우저를 업데이트 하는 일은 없어야 하고, HTTP 명세나 HTML 명세가 변경되어도 웹페이지는 잘 작동해야 합니다.
URL 자원 식별
→ identification of resources, 자원은 url 로 식별되어야 합니다.
/product/${id} 로 요청을 하면, 여기에 해당하는 product 를 줘야한다.
표현을 통한 자원 조작
Manipulation of resources through representations, URL 과 GET, DELETE 등 HTTP 표준 메서드 등을 통해 자원을 조회, 삭제 등 작업을 설명할 수 있는 정보가 담겨야 한다.
getProduct 가 아니라, GET 메소드를 쓰고 /product
Self-descriptive Messages
HTTP Header 에 타입을 명시하고 각 메세지들은 MIME types 에 맞춰 표현되어야 합니다.
예를 들어 .json 을 반환한다면 application/json 으로 명시하기
HATEOAS (Hypermedia As The Engine Of Application State)
강의 내용에서 설명이 좀 부족한 것 같다.
하이퍼링크에 따라 다른 페이지를 보여줘야 하며, 데이터마다 어떤 URL에서 왔는지 명시해주어야 한다.
보통은 href, links, link, url 속성 중 하나에 해당 데이터의 URL 을 담아서 표기해야 합니다.
- 동적 상호작용 제공 : 클라이언트는 고정된 URL 경로를 하드코딩하지 않고, 서버가 제공하는 하이퍼링크를 따라가며 필요한 리소스나 작업을 탐색
- 자체 설명적 메시지: 서버가 응답 메시지에 포함된 링크를 통해 클라이언트가 다음 작업을 수행할 수 있는 정보를 제공합니다.
- 애플리케이션 상태 전환: 링크를 통해 리소스 상태를 바꾸거나, 새로운 리소스를 요청하거나, 작업을 수행할 수 있습니다.
HATEOAS 미적용
json
{
"id": 123,
"name": "John Doe",
"email": "johndoe@example.com"
}
HATEOAS 를 적용한 응답
json
{
"id": 123,
"name": "John Doe",
"email": "johndoe@example.com",
"_links": {
"self": {
"href": "https://api.example.com/users/123"
},
"update": {
"href": "https://api.example.com/users/123",
"method": "PUT"
},
"delete": {
"href": "https://api.example.com/users/123",
"method": "DELETE"
},
"orders": {
"href": "https://api.example.com/users/123/orders"
}
}
}
이 응답에서는 클라이언트가 self, update, delete, orders와 같은 작업을 수행할 수 있도록 하이퍼링크를 제공합니다. • 클라이언트는 이 링크를 활용해 데이터를 업데이트하거나 삭제하며, • 해당 사용자가 주문한 orders 데이터를 조회할 수도 있습니다.
HATEOAS의 장점
-
API 유연성 증가: 클라이언트는 URL을 하드코딩할 필요 없이 동적으로 링크를 탐색하며 API와 상호작용할 수 있습니다.
-
버전 관리 간소화: API 구조가 변경되더라도 클라이언트는 링크를 따라가기만 하면 되므로 API 변경의 영향을 덜 받습니다.
-
문서 의존성 감소: API 응답 자체가 필요한 작업에 대한 정보를 포함하므로, 별도의 문서 없이도 클라이언트가 API를 사용할 수 있습니다.
HATEOAS의 단점
-
구현 복잡성: 서버는 각 리소스에 적절한 하이퍼링크와 메타데이터를 제공해야 하므로 구현 난이도가 증가합니다.
-
성능 부담: 추가적인 링크 정보를 포함하기 때문에 응답 크기가 커질 수 있고, 처리 시간이 늘어날 수 있습니다.
-
지원 부족: 일부 클라이언트 라이브러리나 개발 환경에서 HATEOAS를 직접 활용하기 어려울 수 있습니다.
HATEOAS를 사용해야 할 때
• API 사용자가 특정 리소스에서 어떤 작업을 수행할 수 있을지 동적으로 안내가 필요한 경우.
• 대규모 애플리케이션에서 URL 구조가 자주 변경될 가능성이 높은 경우.
• 클라이언트와 서버 간의 긴밀한 결합을 줄이고 독립성을 높이고자 할 때.
HATEOAS와 RESTful API의 관계
HATEOAS는 REST의 핵심 원칙 중 하나이지만, 모든 RESTful API가 반드시 HATEOAS를 구현해야 하는 것은 아닙니다. RESTful API 설계에서 HATEOAS의 채택 여부는 시스템의 요구 사항과 복잡성에 따라 달라질 수 있습니다.
Stateless
REST API 를 제공하는 서버는 세션을 해당 서버 쪽에 유지하지 않는다는 의미
유저의 상태가 서버에 저장되기 때문에, 세션 방식은 RESTFUL 하지 않다.
Cacheable
HTTP 에선 기본값으로 캐싱이 된다.
Client - Server 구조
클라이언트와 서버가 서로 독립적인 구조를 가져야 합니다. 물론 이는 HTTP 를 통해 가능한 구조입니다.
Layered System
계층 구조로 나누어져 있는 아키텍처.
REST API 의 URI 규칙
- 동작은 HTTP 메소드로만 해야하고, url 에 해당 내용이 들어가면 안된다. 수정은 PUT, 삭제는 DELETE, 추가는 POST, 조회는 GET
- 확장자는 표시하면 안된다.
- 동사가 아닌 명사로만 표기
- 계층적인 내용을 담고 있어야 한다. /집/아파트/전세 처럼 내려가는 구조
- 대문자가 아닌 소문자만 쓰고, 너무 길 경우에는 언더바가 아닌 대시(-) 를 사용
- HTTP 응답 상태코드를 활용. 성공 200, 생성 201, 리다이렉트 301 …
그 외, api 업그레이드를 위해 Version 을 표기 (/wp/v2/posts?page=2)
브라우저 렌더링 과정
아래의 과정이 동시에 일어난다.
-
DOM, CSSOM Tree 생성
DOM Tree : 각각의 태그 노드
CSSOM Tree : CSS 파서에 의해 정해진 스타일 규칙 적용
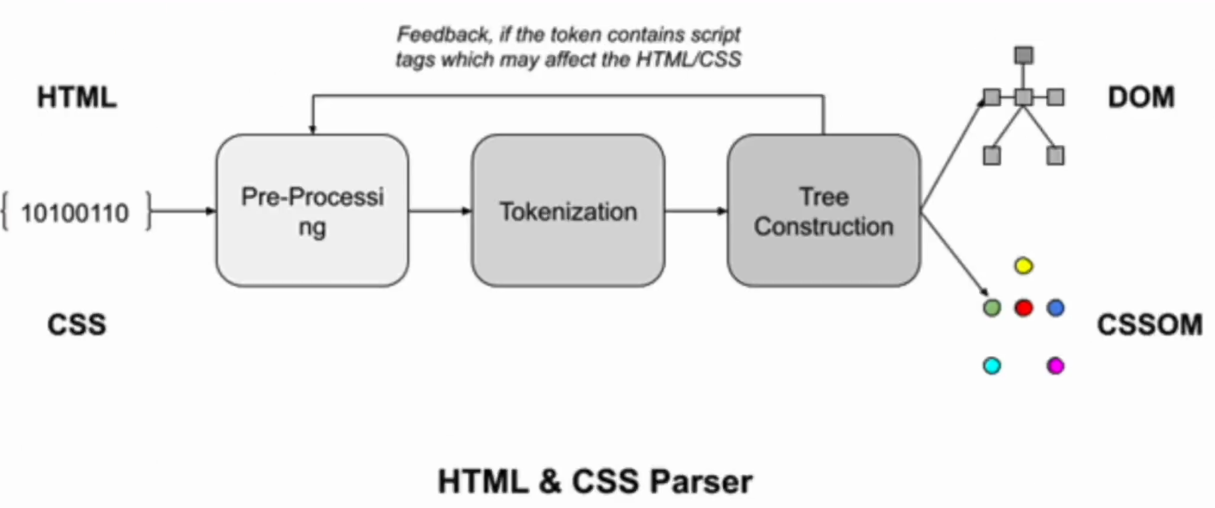 image.png
image.png -
DOM 트리와 CSSOM 트리가 합쳐져 렌더 객체가 생성된다.
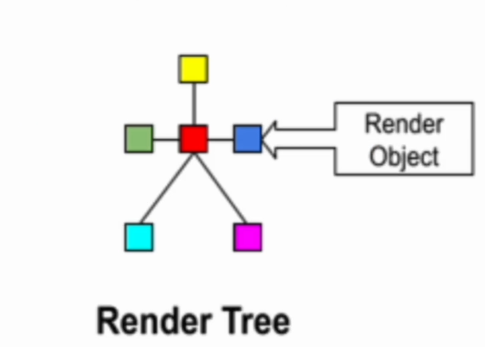 image.png
image.png
이때 display: none 이 포함된 노드는 지워지고, font-size 등 상속적인 스타일은 부모노드에만 위치하도록 설계하는 등의 최적화를 거쳐 렌더 레이어가 완성 된다.
display: none 은 렌더트리에서 삭제 되지만, visibility: hidden 은 요소를 보이지 않게 할 뿐 여전히 레이아웃에서 공간을 차지한다.
또한 렌더 레이어가 완성될 때, GPU 에서 처리되는 부분이 있으면 이 요소들은 강제적으로 그래픽 레이어로 분리된다.
그래픽 레이어는 리플로우와 리페인트를 유발하지 않는다.
- 레이아웃 잡기 (Layout)
- 렌더레이어를 대상으로 칠하기 (Paint)
-
레이어 합치기 (Composite Layer) 및 표기
각각의 레이어로부터 비트맵이 생성되고, GPU에 텍스쳐로 업로드 됩니다. 그 다음 텍스쳐들은 서로 합쳐져 하나의 이미지로 렌더링되며 화면으로 출력됩니다.
💡 렌더트리와 DOM 트리는 1:1 대응일까요?
아닙니다. DOM 트리 > 렌더 객체 > 렌더 트리가 되는 과정에서 display: none 으로 사라지는 렌더 객체들이 있을 수 있기 때문.
아닙니다. DOM 트리 > 렌더 객체 > 렌더 트리가 되는 과정에서 display: none 으로 사라지는 렌더 객체들이 있을 수 있기 때문.
www.naver.com 을 주소창에 입력했을 때 생기는 과정, 그리고 DNS 까지 설명해주세요
강의 답변
리다이렉트, 캐싱, DNS, IP 라우팅, TCP 연결 구축을 거쳐 요청, 응답이 일어나는 TTFB(TIme TO First Byte) 가 시작되고 이후 컨텐츠를 다운받게 되고, 브라우저 렌더링 과정을 거쳐 네이버라는 화면이 나타나게 됩니다.리다이렉트
리다이렉트가 있다면 리다이렉트를 진행하고, 없다면 그대로 해당 요청에 대한 과정이 진행
캐싱
해당 요청이 캐싱이 가능한지, 가능하지 않은지를 파악합니다. 캐싱이 이미 된 요청이라면 캐싱된 값을 반환하며, 캐싱이 되지 않은 새로운 요청이라면 그 다음 단계로 넘어갑니다.
캐싱은 요청된 값의 결과값을 저장하고 그 값을 다시 요청하면 다시 제공하는 기술입니다.
브라우저 캐시와, 공유 캐시로 나뉘어집니다.
브라우저 캐시
쿠키, 로컬스토리지 등을 포함한 캐시 (개인, private 캐시)
공유 캐시
클라이언트와 서버 사이에 있으며, 사용자간에 공유할 수 있는 응답을 저장할 수 있다. 예를 들어, 요청한 서버 앞 단에 프록시 서버가 캐싱을 하고 있는 것. 이를 리버스 프록시를 둬서 내부 서버로 포워드한다고도 말합니다.
DNS
Domain Name System 은 계층적인 도메인 구조와 분산된 데이터베이스를 이용한 시스템으로,
FQDN 을 인터넷 프로토콜인 IP 로 바꿔주는 시스템입니다.
이는 DNS 관련 요청을 네임서버로 전달하고, 해당 응답값을 클라이언트에게 전달하는 Resolver,
도메인을 IP 로 변환하는 네임서버 등으로 이루어져있습니다.
FQDN
FQDN (Fully Qualified Domain Name) 은 호스트와 도메인이 합쳐진 완전한 도메인 이름을 말합니다.
www.naver.com 에서 www 등은 호스트 부분 혹은 서브 도메인, naver.com 은 도메인이라고 합니다.
DNS 캐싱
미리 해당 도메인 이름을 요청한 적이 있다면, 로컬 PC 에 자동적으로 저장됩니다.
브라우저 캐싱과, OS 캐싱이 있습니다.
IP 라우팅
해당 IP 를 기반으로 라우팅, ARP 과정을 거쳐 실제 서버를 찾습니다.
TCP 연결 구축 (HTTP ~2.0)
브라우저가 TCP 3Way handshake 및 SSL 연결 등을 통해 연결을 설정합니다.
이후에 요청을 보냄으로써 서버로부터 응답을 받습니다.
QUIC 연결 (HTTP 3.0)
컨텐츠 다운로드
요청한 컨텐츠를 서버로부터 다운 받습니다.
처음 다운로드를 시작할 때, TTFB (Time To First Byte) 라고 합니다.
브라우저 렌더링
받은 데이터를 바탕으로 브라우저 엔진이 브라우저 렌더링 과정을 거쳐 화면을 만듭니다.
이더넷 프레임은 무엇이며, 구조가 어떻게 되나요?
 image.png
image.png
이더넷프레임이란 데이터 링크계층의 데이터 단위이며 이더넷 프레임을 기반으로 데이터가 전달 되며 다음과 같은 필드로 구성되어있습니다.
**Preamble** : [7바이트] 이더넷 프레임이 시작임을 알려준다.
**SFD** : [1바이트] Start frame delimiter, 다음 필드부터 주소필드가 시작됨을 알려줍니다.
**Address** : [6, 6바이트] 목적지 주소, 시작지 주소입니다.
**EtherType** : [2바이트] 데이터링크계층 위의 IP 프로토콜을 정의합니다. (IPv4, Ipv6)
**Payload** : [가변바이트] 데이터 또는 페이로드라고 합니다. 가변길이 필드입니다. 해당 필드는 이진데이터(0과1로 이루어진 데이터)로 구성됩니다. IEEE 표준은 최대 페이로드를 1500 바이 트로 지정하고 있습니다.
**FCS** : [4바이트] frame check sequence이며 수신측의 에러검출을 위해 삽입하는 필드입니 다. CRC 에러검출 기법에 의해 생성된 비트배열이 여기에 담깁니다. 비트배열을 기반으로 수신된 데이터가 손상되었는지를 확인하고, 에러 확인 시에는 해당 프레임을 폐기하고 송신측에 재전송을 요구하기 위한 필드입니다. CRC 알고리즘에 의해 만들어진 비트 배열이 담기는 필드
CORS란 무엇인가요?
Origin
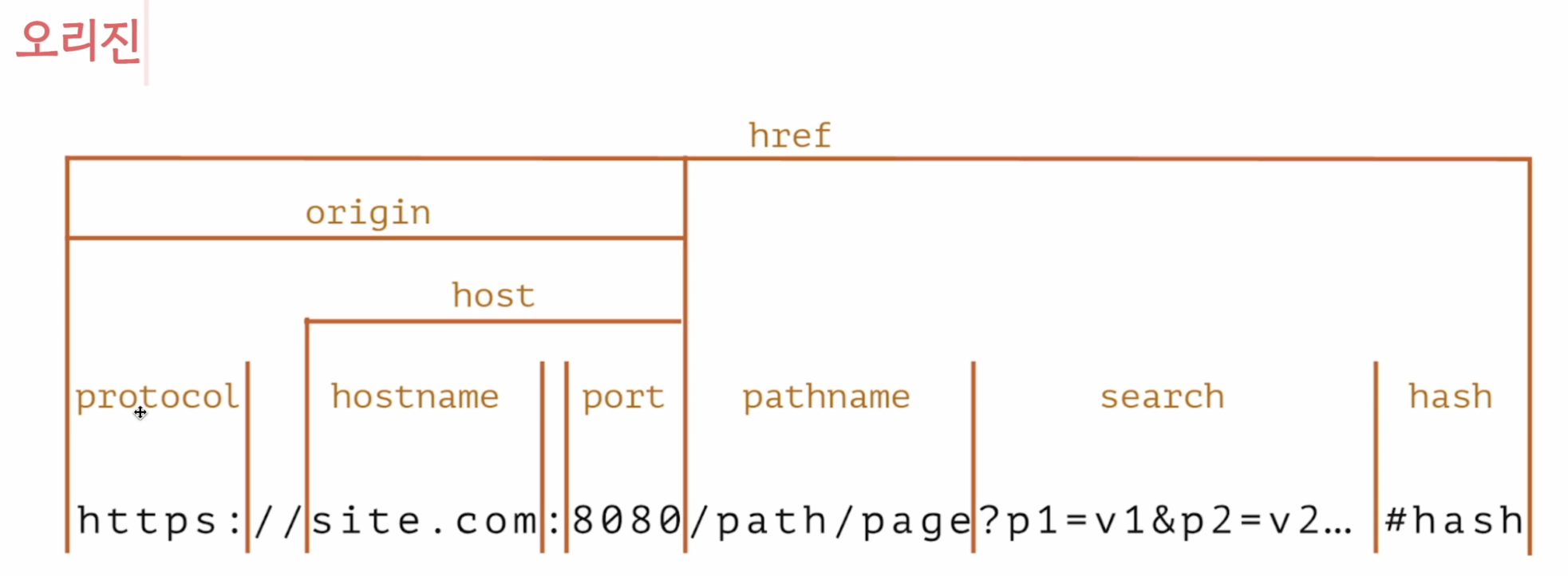 image.png
image.png
오리진은 프로토콜 + 호스트네임 + 포트
예를 들어, https://shopping.naver.com/home 에서
https , shopping.naver.com , 8080
SOP (Same Origin Policy)
브라우저 상에서 오로지 같은 오리진끼리만 요청을 허가하는 보안 정책.
브라우저 상에서 다른 오리진끼리는 통신이 불가능하다.
다른 오리진에서 요청을 하는 공격에 방지하기 위함
CORS (Cross Origin Resource Sharing)
다른 오리진과 통신을 해야하는 일이 있을 수 있기 때문에, SOP 보다 조금 느슨한 규칙
포트번호만 달라도 오리진이 다르기 때문에 개발 과정에서 백/프 끼리도 보통 오리진이 다르다
HTTP 헤더를 기반으로 브라우저가 다른 오리진에 대한 리소스(image, css, js, video 등) 로드를 허용할지 말지에 대한 규칙
Preflight Request, Simple Request
CORS는 브라우저가 다른 출처(origin)의 리소스에 접근할 때 안전을 보장하기 위해 사용하는 메커니즘입니다. 요청은 크게 두 가지로 나뉩니다
1. Simple Request (단순 요청)
정의
- 브라우저가 사전 확인(preflight)을 생략하고 직접 요청을 서버에 보내는 요청입니다.
- CORS 규칙에서 Simple Request는 특정 조건을 만족해야 합니다.
Simple Request의 조건
Simple Request가 되기 위해서는 아래 조건을 모두 충족해야 합니다:
- HTTP 메서드가 다음 중 하나여야 합니다:
GETPOSTHEAD
- 헤더(Header):
- 요청에 사용된 헤더가 CORS에서 허용된 간단한 헤더(Simple Headers)만 포함해야 합니다.
- 허용된 간단한 헤더:
AcceptAccept-LanguageContent-LanguageContent-Type(단, 값이application/x-www-form-urlencoded,multipart/form-data, 또는text/plain일 경우만 허용)
- Content-Type:
- 요청 본문(
Body)의Content-Type값이 아래 중 하나여야 합니다:application/x-www-form-urlencodedmultipart/form-datatext/plain
- 요청 본문(
- Credentials:
- 요청에
Authorization헤더나 쿠키와 같은 자격 증명(크리덴셜)이 포함되지 않아야 함 (withCredentials가false).
- 요청에
동작 방식
- 브라우저는 요청을 바로 서버에 보냅니다.
- 서버는 요청의 출처(origin)와 헤더를 보고 허용 여부를 판단합니다.
- 서버가 허용하면 브라우저는 응답을 처리합니다.
2. Preflight Request (사전 요청)
정의
- 요청이 Simple Request 조건을 충족하지 않으면 브라우저는 Preflight Request를 먼저 보냅니다.
- Preflight Request는 실제 요청 전에 서버가 해당 요청을 허용할지 여부를 확인하는 안전성 검사입니다.
Preflight Request의 동작
- 브라우저는 HTTP OPTIONS 메서드로 사전 요청을 보냅니다.
- Preflight Request에는 아래와 같은 정보를 포함합니다:
Origin: 요청의 출처.Access-Control-Request-Method: 실제 요청에 사용될 HTTP 메서드.Access-Control-Request-Headers: 실제 요청에서 사용될 커스텀 헤더(있을 경우).
- 서버는 Preflight Request에 대해 응답합니다:
Access-Control-Allow-Origin: 허용된 출처.Access-Control-Allow-Methods: 허용된 HTTP 메서드.Access-Control-Allow-Headers: 허용된 커스텀 헤더.- 응답 상태 코드가 200이면 브라우저는 실제 요청을 보냅니다.
Preflight가 필요한 조건
Preflight Request는 다음 중 하나 이상에 해당할 때 발생합니다:
- 요청 메서드가
GET,POST,HEAD가 아닌 경우 (PUT,DELETE,PATCH등). - 요청 헤더가 간단한 헤더 외의 커스텀 헤더를 포함하는 경우.
Content-Type이application/x-www-form-urlencoded,multipart/form-data,text/plain이 아닌 경우 (예:application/json).- 요청에 자격 증명(크리덴셜, 예:
Authorization헤더나 쿠키)이 포함된 경우.
네이글 알고리즘이란 무엇인가요?
네이글 알고리즘은 네트워크의 효율성을 높이기 위해 네트워크를 통해 전송되어야 하는 패킷의 수를 줄이고 적은 양의 데이터를 자주 보내면 발생되는 대역폭 낭비를 막아주는 방법입니다.
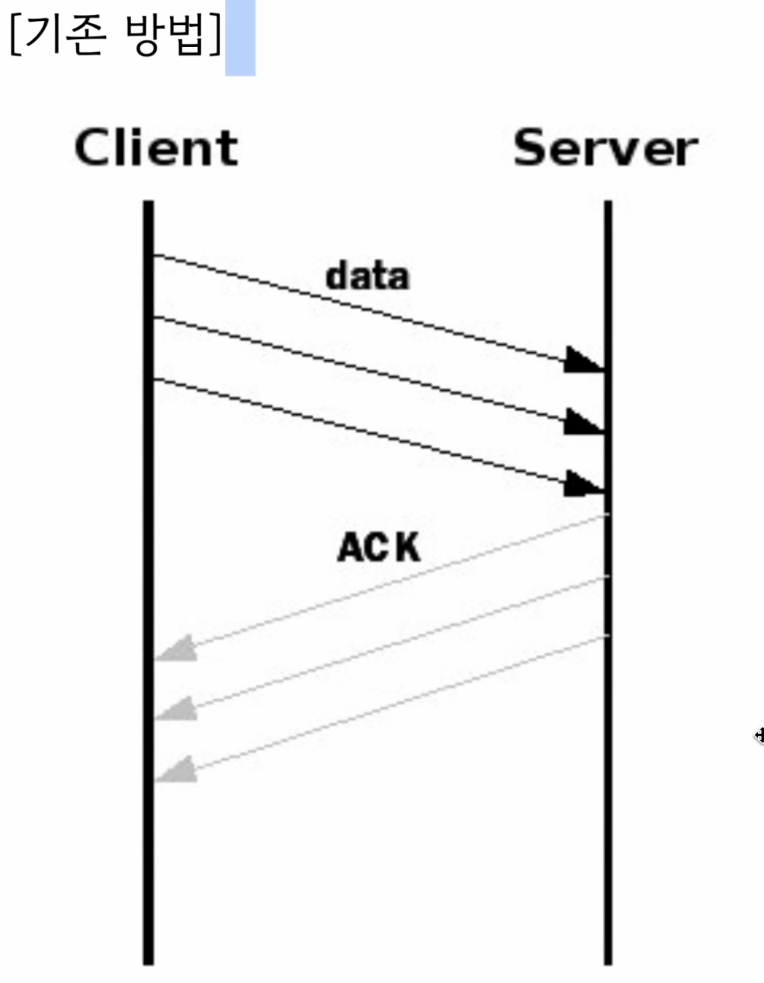 image.png
image.png
기존 방법과 다르게 패킷을 보낼 때 고정 크기의 버퍼에 모아두고 버퍼에 어느정도 차면 그 때 보내고, 다시 ACK 가 오면 버퍼에 찬 데이터를 보내는 방법
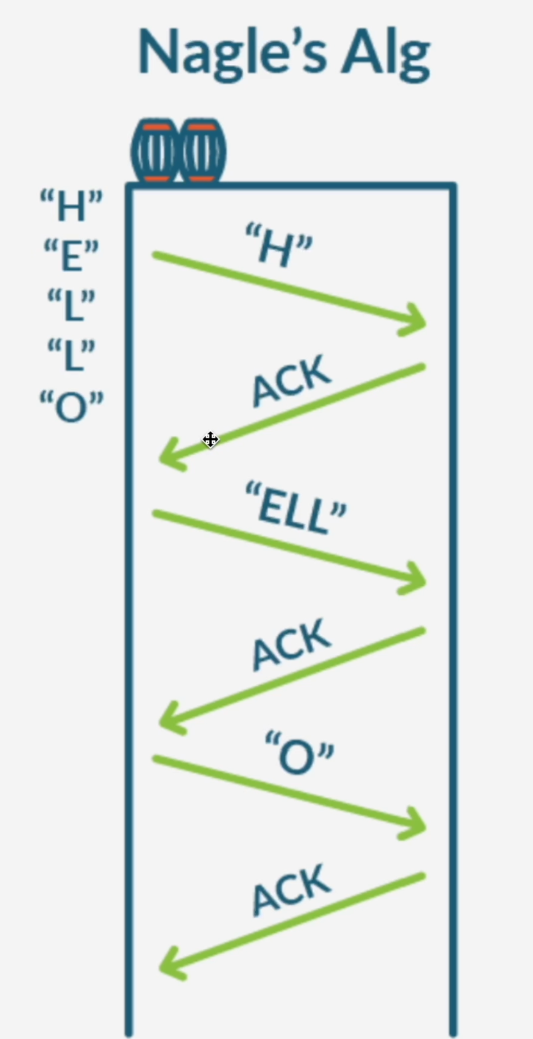 image.png
image.png
네이글 알고리즘의 장점
- 전송하는 패킷의 수가 줄어들기 때문에 네트워크의 혼잡도를 줄이고 패킷 손실률을 줄일 수 있다.
- 작은 패킷들을 많이 전송할 때, 각 패킷에 포함된 헤더의 크기가 커져서 대역폭 소모가 많이 발생할 수 있다. 패킷의 수를 줄임으로써 이러한 오버헤드를 줄일 수 있다.
네이글 알고리즘의 단점
- 작은 패킷의 수를 줄이기 위해 데이터를 버퍼링하고, 충분한 양의 데이터가 모일 때 까지 패킷 전송을 지연시킨다.
- ACK를 받기 전까지 데이터를 전송하지 않기 때문에 지연시간이 발생할 수 있다. (실시간이 중요하다면 사용하기 힘들다)
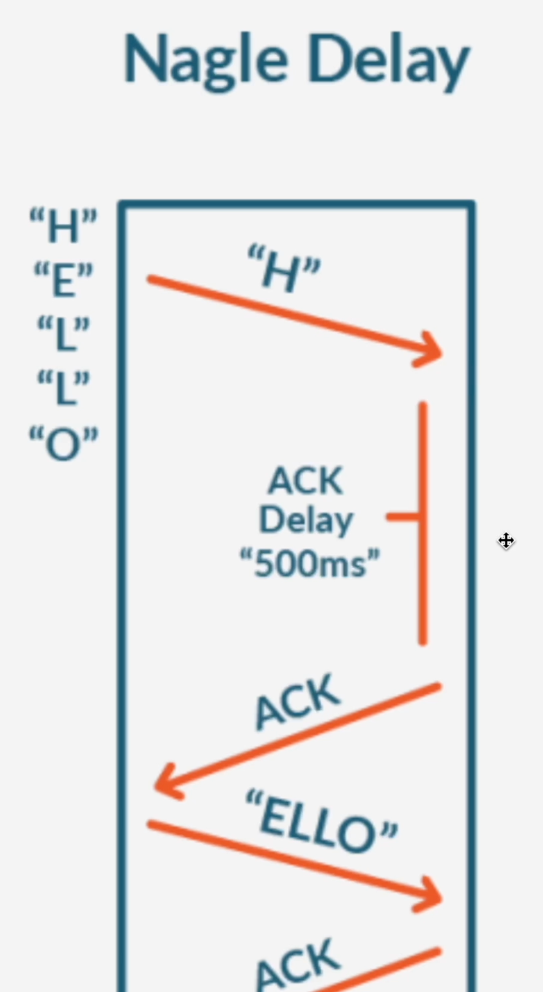 image.png
image.png
HTTP 의 멱등성에 대해 설명해주세요
HTTP 멱등성(idempotent)이란 하나의 요청이 아닌 여러번 동일한 요청을 보냈을 때 서버가 같은 상태를 가지는 것을 멱등성이라고 합니다.
https://docs.tosspayments.com/blog/what-is-idempotency
멱등성을 가지는 메소드
GET (안전한 메소드)
서버에서 정보를 가져오는 것을 여러 번 해도, 동일한 정보를 가져온다.
HEAD (안전한 메소드)
헤드는 GET 요청이 생성하는 응답의 헤더를 검색하는데 사용됩니다.
따라서 서버의 상태를 변경하지 않습니다.
OPTIONS (안전한 메소드)
대상 리소스의 통신 옵션 ( 서버에서 지원하는 HTTP 메서드 등)을 가져올 때 사용
PUT (안전한 메소드는 아님)
서버에 있는 데이터를 아예 교체하기 때문에 여러 번 보내도 똑같은 데이터로 교체될 것입니다.
DELETE (안전한 메소드는 아님)
삭제 작업을 반복해도 시스템 상태가 더 이상 변경되지 않습니다.
그런데 흠..
예를 들어 DELETE /post/lastest 라고 해보자. 가장 최신 포스트를 지우게 된다고 하면 서버의 상태가 바뀌지 않나?
또한 만약 DELETE /post/abc 인 상황에서 abc 라는 리소스가 여러 개라면? DELETE 는 abc 리소스를 하나만 지우는 상황이라면 어떻게 될까?
이러면 또 멱등성을 보장할 수 없는게 아닌가?
DELETE는 멱등성을 보장하는 메서드이지만, 대상 리소스를 정확히 지정해야 합니다. 예를 들어,DELETE /posts/123와 같이 구체적인 리소스를 명시해야 합니다.DELETE /posts/last와 같이 마지막 게시글을 삭제하는 요청은 상태 변화가 계속 일어나므로 멱등성을 가지지 않습니다.- 이런 경우에는
POST를 사용하는 것이 더 적절합니다.
요약: DELETE는 멱등성을 보장하므로 상태 변화가 없을 때 사용해야 합니다. 상태가 계속 바뀌는 경우에는 POST를 사용하는 것이 HTTP 스펙상 더 맞습니다.
POST
서버에 동일한 요청을 여러 번 보내면, 보낸 만큼 생성 될 것이기 때문에 서버의 상태가 바뀌게 된다.
PATCH
리소스를 부분적으로 업데이트 하게 되는데, 멱등성의 여부는 PATCH 를 실행하는 방법에 따라 달라진다.
예를 들어 특정 부분을 새롭게 교체하는거라면 멱등성을 가지지만, 하나씩 증가하거나 빼기, 배열에 요소 추가 등의 방식은 멱등성을 가지지 않는다.
함수형 프로그래밍이 생각나네
HTTP 멱등성을 고려한 API 설계
POST 메서드의 경우 idempotency Key를 보내서 동일한 요청인지를 식별하게 합니다. 이를 통해 동일한 작업의 재시도를 인식하고 한 번만 처리되도록 합니다. 이는 중복 트랜잭션을 피해야 하는 결제 처리 API에서 자주 사용됩니다.
멱등성이 중요한 이유
- 일관성 : 보통 반복되는 요청이 단일 요청과 동일한 효과를 갖도록 보장하는 것은 시스템 전반에 걸쳐 일관된 상태를 유지하는 데 도움이 됩니다.
- 유지보수성 : 멱등성을 가진 HTTP메서드로 AP로 통신하는 부분에 있어서는 재시도를 처리할 때의 사이드이펙트를 고려한 복잡한 로직을 구현할 필요가 없기 때문에 이 부분을 잘 고려해서 설계한다면 유지보수성이 증가 됩니다.
Subscribe to hoeeeeeh
Get the latest posts delivered right to your inbox
