[네부캠 챌린지] Day 01 ~ 19 정리
Day01 학습 정리
확장성?
나는 주로 코드를 작성할 때, 나중에 내가 이 코드를 다시 수정해야 하는 일이 생긴다면 최대한 쉽게쉽게 수정할 수 있도록 짜고 싶다는 생각을 한다.
그래서 최대한 바뀔 수 있어보이는 것들은 바뀌어도 문제가 없게끔 작성하려고 노력한다. 하지만 이것 때문에 왔던 길을 다시 되돌아가기도 하고 설계했던 부분을 다시 거슬러 올라가는 일도 빈번하다.
다른 사람들은 코드를 짤 때 어떤 것을 중요하게 여기면서 코드를 짜는지 궁금하다.
static
확장성을 높여보고자 회의실의 이름, 최대 인원수를 변경할 수 있도록 설계했다. 그러면서 static 을 써보려고 생각을 했다. 자바스크립트에서도 ES6 이후로 static 키워드를 사용할 수 있다고 한다. 실제 사용한 코드는 아니고, 예시로 설명하자면 아래 코드와 같다.
text
class utility {
static multiply(a, b) {
return a * b;
}
static plus(a, b) {
return a + b;
}
}
console.log(utility.multiply(3, 5));
// 15
utility 클래스를 하나 만들고 멤버변수 혹은 멤버 메소드에 static 키워드를 붙여주고 사용했다.
클래스의 객체를 따로 만들지 않고 바로 multiply 함수를 사용해도 결과가 잘 나온다.
처음에는 static 메소드도 사용할 일이 있겠다 싶어 class 로 만들고, static 메소드와 변수를 사용하겠다는 설계를 했었는데
구현을 하다보니 static 메소드는 딱히 필요가 없어졌고 오히려 enum 을 사용해도 괜찮았겠다는 생각이 들었다.
static 를 사용하기 좋은 경우는 객체들간에 전부 공유되는 변수/메소드가 필요할 때 좋다.
enum
아쉽게도 타입스크립트가 아닌 자바스크립트에는 enum이 구현되어 있지는 않다. 그저 Object 타입의 객체로 만들어주는 것인데, Object.freeze()를 통해 불변객체로 만들어서 활용하는 정도라고 한다.
javascript
Object.freeze({
RED: "red",
GREEN: "green",
BLUE: "blue",
});
함수 분리
코드를 작성하면서 코드가 길어지거나 중첩이 깊어질 수록 가독성이 떨어진다는건 알고 있지만 함수를 여러 개로 분리해서 짜는것도 깔끔하게 작성하기는 쉽지 않다.
함수를 분리할 때 중복되는 코드 나 기능별로 나눌 수 있을 것 같은 함수를 위주로 분해를 많이 했다.
commit 메세지
• feat : 새로운 기능 추가, 기존의 기능을 요구 사항에 맞추어 수정
• fix : 기능에 대한 버그 수정
• build : 빌드 관련 수정
• chore : 패키지 매니저 수정, 그 외 기타 수정 ex) .gitignore
• ci : CI 관련 설정 수정
• docs : 문서(주석) 수정
• style : 코드 스타일, 포맷팅에 대한 수정
• refactor : 기능의 변화가 아닌 코드 리팩터링 ex) 변수 이름 변경
• test : 테스트 코드 추가/수정
• release : 버전 릴리즈
• typo : 오타 수정
커밋 기준은 돌아갔을 때 버그가 없어야 한다.
내가 하는 커밋의 기준은 너무 큰 것 같다. 지금보다는 조금 더 짧은 주기로 커밋 해보자.
입력값이 정수형이라면?
이번 문제를 해결하면서 필요한 문자열을 적절히 파싱해주는 과정을 거치고 있지만, 정수형으로 주어진다면 파싱을 하지 않아도 될 것이다.
또한 파싱을 일부는 안하고 일부는 하는 방식으로 접근했었는데 정수형으로 주어지면 이렇게 일부를 따로 고려할 필요도 없어진다.
Github Pull request
Fork 원본 저장소를 자신의 계정으로 복사
Clone git clone <저장소 URL=""> 저장소를 로컬 환경으로 복사
Branch git checkout -b <브랜치 이름=""> 새로운 브랜치를 만들고 해당 브랜치로 체크아웃
Commit git commit -m 변경 사항을 커밋 메세지와 함께 커밋
Push git push <리모트 이름=""> <브랜치 이름=""> 변경 사항을 원격 저장소에 Push
이후 원본 저장소에 Pull Request 생성
Day02 학습 정리
Virtualization & Emulation
가상화와 에뮬레이션의 차이는 무엇일까?
Virtualize 와 Emulate 의 차이는, Virtualize는 선택한 시스템으로 독립적인 컨테이너를 만들어서 사용하는 것이고, Emulate는 기존의 로컬이 선택한 시스템이 동작하는 것처럼 흉내내는 것이다. Virtualize 의 경우 해당 시스템이 동작하는 그대로,선택한 시스템의 운영체제 자체를 네이티브로 돌아가기 때문에 성능이 비교적 좋다. 또한 호스트 머신과 완벽하게 분리되어 돌아가기 때문에 직접적으로 마운트 하지 않은 다른 시스템들과는 서로 영향을 끼치지 않는다. 하지만 CPU 아키텍처가 다르거나 하는 이유로 가상화를 할 수 없는 경우가 있다.
Emulate 의 경우에는 다른 시스템을 모방해서 동작하는데 오버로드가 생길 수 있어 성능이 비교적 좋지 않다. 말 그대로 선택한 시스템의 하드웨어가 행동하는 것 처럼, 소프트웨어가 작동하는 것이다.
그러나 CPU 아키텍처가 다른 경우에도 사용할 수 있다는 큰 장점이 있다.
공개키 개인키?
ssh 접속은 비밀번호로도 가능하지만 보안에 취약해 보통 공개키와 개인키를 활용한다.
대칭키와 비대칭키
암호화에는 대칭키를 이용하거나, 비대칭키를 이용할 수 있다.
대칭키는 암호화하는 키와 복호화하는 키가 같은 경우를 뜻한다. 누군가가 A라는 키로 암호화해서 나에게 건네주었다면 나도 반드시 A라는 키가 있어야한다.
하지만 이 방법은 A라는 키를 나에게 있어야 복호화 할 수 있기 때문에 결국 A라는 키를 전달해 주어야한다. 전달과정에서 보안이 문제가 될 수 있다는 단점이 존재하게 된다.
비대칭키 는 암호화하는 키와 복호화하는 키가 다른 경우이다. 공개키 와 개인키 가 서로 비대칭(서로 다른 키)을 이루어서 암호화하거나 복호화할 수 있다.
공개키는 개인키에 의해서 만들어지는데 개인키에 대응하는 공개키는 오직 1개인 반면, 공개키로는 개인키를 유추할 수 없다.
따라서 공개키는 노출되어도 되지만 개인키는 노출되어서는 안된다.
쉘 스크립트 문법
자주 사용되는 문법들을 위주로 정리해보려고 한다.
grep
<grep [옵션] 패턴 [파일…]> 의 형식으로 사용할 수 있지만 보통은 파이프로 많이 사용한다.
특정 패턴과 일치하는 줄을 찾아 출력하는 아주 강력한 텍스트 검색 도구이다.
bash 의 if문
shell
if [ 조건문 ]; then
elif [ 조건문 ]; then
else
fi
의 형태이다.
셔뱅
#!/bin/bash 는 Shebang(셔뱅)이라고 불리며, 스크립트 파일의 첫 줄에 위치하는 특별한 주석이다.
이 줄은 운영체제에게 해당 스크립트를 실행할 인터프리터(interpreter)를 지정하는 역할을 한다.
#!/usr/bin/env python3 처럼 입력하면 python 인터프리터를 찾아 실행하게 되는 것이다.
또한 crontab 같은 스케줄러는 셔뱅을 통해 인터프리터를 파악하게 되므로 반드시 필요하다.
$# 파라미터
bash multiply.sh 3 5 와 같이 3과 5를 파라미터로 넘겨줬을 때 코드 내부에서는 $(숫자) 로 첫 번째 파라미터부터 받기 시작한다. $@ 은 모든 파라미터를 담고 있다.
for
shell
for i in $@; do
done
Day 03 학습 정리
컴파일러 이론
컴파일러는 고급 프로그래밍 언어로 작성된 소스 코드를 컴퓨터가 실행할 수 있는 저수준 언어(주로 어셈블리어나 기계어)로 변환하는 프로그램이다.
이 프로그램의 단계는 Tokenizer -> Lexer -> Parser 로 나뉘는데, 이에 대해 한 번 알아보자.
Tokenizer
토크나이저는 소스 코드를 의미 있는 최소 단위인 토큰 으로 나누는 역할을 한다.
예를 들어, 아래의 소스 코드가 토크나이저에 의해 나누어진다고 가정해보자.
javascript
let a = "my Tokenizer";
위의 소스코드를 왼쪽부터 읽어보면, l -> le -> let -> let(공백) -> let(공백)a … 의 방식일 것이다.
l, le 는 의미가 있지 않은 반면, 자바스크립트에서 변수를 선언할 때 사용하는 let는 의미를 가지게 된다.
따라서 이 경우에는 공백을 기준으로 코드를 쪼갠다면 그 결과물들이 전부 의미 있는 최소 단위인 토큰이 될 것처럼 보인다.
하지만 여기서 무작정 공백으로 나눈다면 “my 와 Tokenizer” 로 분리되게 되는데, 이는 프로그래머가 의도한 것과는 달라보인다.
따라서 이렇게 구분하기 위한 것에는 공백, 따옴표 등등의 기준을 정규식 으로 미리 정의하고 분리한다.
이 과정에서 불필요한 공백(trim) 이나 주석을 제거하기도 한다.
[let, a, =, ‘my Tokenizer’]
Lexer (어휘 분석)
이렇게 토크나이저에 의해 분리된 토큰은 lexer 에 입력으로 들어오게 된다.
lexer 는 토큰들의 의미를 파악해서 토큰의 종류와 값을 나타내는 (ex. 키워드, 식별자, 연산자 및 리터럴) 같은 개별 토큰 객체로 반환한다. 토큰의 종류(type) 결정 (예: 키워드, 식별자, 연산자, 리터럴) 토큰의 값(value) 추출 (예: 식별자의 이름, 숫자 리터럴의 값)
[let, a, =, ‘my Tokenizer’] -> [keyword(let), identifier(a), operator(equal), literal(‘my Tokenizer’)]
Parser
lexer 에 의해 만들어진 토큰 객체들은 parser 로 넘어온다. parser 는 이 토큰 객체들로 문법 규칙에 따라 구문 분석을 수행한다.
구문 분석을 수행하며 파스 트리(Parse Tree) 또는 추상 구문 트리(AST, Abstract Syntax Tree)로 만드는데,
ast 그려주는 사이트! 여기에 좋은 사이트가 있었으므로 참고해서 그려보자.
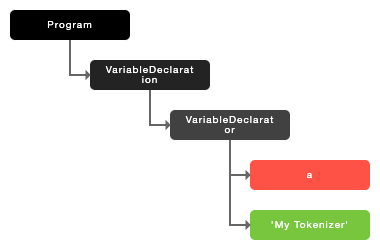 image.png
image.png
let a = 'My Tokenizer' 를 AST 로 표현한 것이 위의 트리인데, let 이라는 키워드는 ‘변수 선언’(Variable Declaration)이므로 루트노드가 ‘변수 선언’ 인 것을 알 수 있다.
이후에는 (할당)표현식으로 나누어지는데, a는 Identifier, =는 Operator, “My Tokenizer” 는 StringLiteral 토큰 객체로 각각 나뉘어진다.
정규 표현식
위의 컴파일러의 lexer는 주로 정규 표현식을 통해서 토큰의 종류와 값을 파악한다. 또한 정규식은 여러 분야에서 다양하게 쓰인다.
예전에는 정규 표현식 대신 조건문을 사용했었는데, 정규 표현식의 사용이 훨씬 코드를 단축시켜주는 것 같다. 다만 경우에 따라서는 if 문이 가독성 자체는 좋을 수도 있겠다라는 생각도 들어 적절히 잘 사용해야겠다.
정규식에 사용되는 규칙을 전부 다 외우는건 조금 힘들어 보인다. 그 중에서 기본적인 규칙에 대해서만 외우고, 자잘한것은 찾아보면서 진행하는 것이 가장 좋아 보인다. 정규식에 유용한 사이트
text
문자 클래스 (Character Classes): [abc]처럼 대괄호 안에 문자들을 나열하여 해당 문자들 중 하나와 매치되는 패턴을 만든다
수량자 (Quantifiers): *, +, ?, {n}, {n,m} 등을 사용하여 앞의 문자나 문자 클래스가 반복되는 횟수를 지정
앵커 (Anchors): ^, $, \\b 등을 사용하여 문자열의 시작, 끝, 단어 경계 등 특정 위치를 지정
그룹화 (Grouping): () 괄호를 사용하여 여러 문자를 하나의 그룹으로 묶고, 수량자나 다른 연산을 적용
이스케이프 문자 (Escape Characters): \\, \\d, \\w, \\s 등 특수 문자를 사용하여 특정 문자 클래스를 나타낸다
주로 공백을 표현할 때는 \\s 를 사용하는데, 만약 공백이 0개 이상 을 표현하고 싶으면 * 을(\s*), 1개 이상 을 표현할 때는 + (\s+)를 사용한다.
{n}: 앞의 문자나 문자 클래스가 정확히 n번 반복되어야 함을 나타냅니다. 예시: \d{3} (정확히 3개의 숫자와 매칭) {n,}: 앞의 문자나 문자 클래스가 n번 이상 반복되어야 함을 나타냅니다. 예시: \d{2,} (2개 이상의 숫자와 매칭) {n,m}: 앞의 문자나 문자 클래스가 n번 이상 m번 이하 반복되어야 함을 나타냅니다. 예시: \d{2,4} (2개 이상 4개 이하의 숫자와 매칭)
Day 04 학습 정리
Day04
프로세스와 메모리
학교에서 ‘컴퓨터 구조’ 수업 시간에 들었던 프로세스, 메모리 관리를 막상 사용해보려고 하니 쉽지가 않았다.
그래서 전반적인 개념에 대해서 다시 한 번 복습해보는게 좋을 것 같다.
프로세스와 스레드
프로세스와 스레드의 역할은 상당히 유사해보여서 자주 헷갈리곤 한다.
| 구분 | 프로세스 (Process) | 스레드 (Thread) |
|---|---|---|
| 대표 키워드 | Isolation (독립적) |
Concurrency (동시성) |
| 정의 | 실행 중인 프로그램의 인스턴스 | 프로세스 내에서 실행되는 작업의 시퀀스 |
| 메모리 | 독립적인 메모리 공간 |
같은 프로세스 내에서 메모리 공간을 공유 |
| 자원 공유 | 자원을 독립적으로 할당받음 |
같은 프로세스 내에서 자원(메모리, 파일 등)을 공유 |
| 생성 방법 | 운영 체제의 프로세스 생성 시스템콜(fork 등) | 프로세스 내에서 생성 |
| 실행 단위 | 독립적으로 실행 |
다른 스레드와 병렬로 실행 가능 |
| 오류 영향 | 한 프로세스의 오류가 다른 프로세스에 영향을 미치지 않음 |
한 스레드의 오류가 같은 프로세스의 다른 스레드에 영향을 줄 수 있음 |
| 실행 속도 | 상대적으로 느림 → 프로세스 간의 통신(IPC) 비용이 높음 |
상대적으로 빠름 → 스레드 간의 통신 비용이 낮음 |
| 스케줄링 | 독립적인 스케줄링 |
동일한 프로세스 내에서 스케줄링됨 |
프로세스에서 메모리 관리
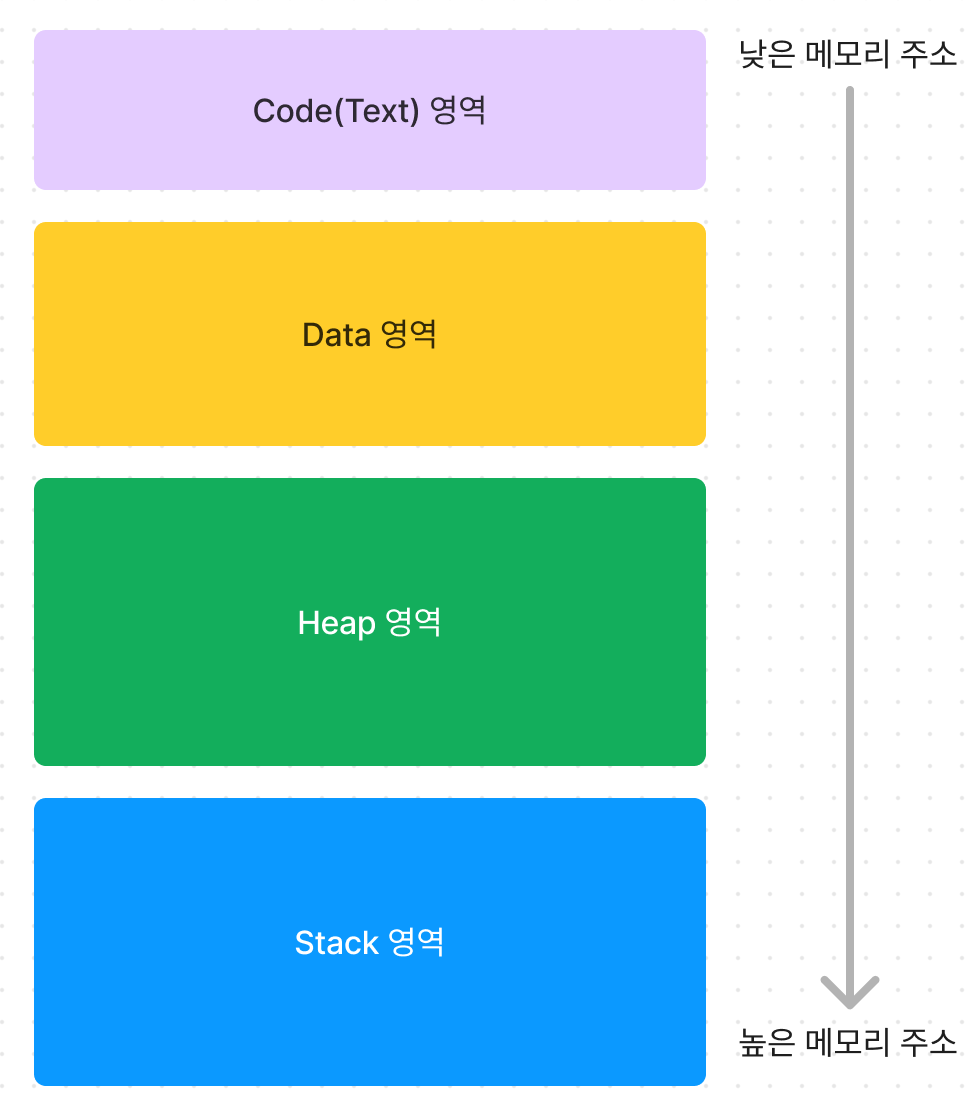 image.png
image.png
프로세스가 OS에 의해 할당받는 메모리는 Code(Text)영역, Data영역, Heap영역, Stack영역으로 나뉘게 된다.
Code(Text)영역
Code 영역은 실제 프로그램의 코드(명령어)가 저장되는 영역 이다.
CPU는 이 영역에서 명령어를 가져가서 실행하게 된다.
생성 → 코드 영역은 프로그램이 시작할 때 할당된다.
소멸 → 종료될 때 사라진다.
Data 영역
Data 영역에는 프로그램의 전역 변수와 정적(static) 변수가 저장되는 영역이다.
생성 → 데이터 영역은 프로그램이 시작할 때 할당된다.
소멸 → 종료될 때 사라진다.
Heap 영역
Heap 영역은 동적 메모리 할당에 사용되는 영역이다. 대표적으로 malloc 이나, new 키워드 등이 있다.
Stack 영역과 반대로, 낮은 메모리 주소부터 할당하기 시작한다.
생성 → 힙 영역은 동적 메모리 할당 요청(malloc, new…)이 있을 때 할당된다.
소멸 → 메모리를 해제(free, delete ...) 할 때 사라진다.
Stack 영역
Stack 영역에는 지역 변수와, 매개 변수가 저장되는 영역이다.
그 외에도 다양한 정보들이 스택 영역에 쌓이게 되는데, 이렇게 하나의 함수에 대한 정보들이 쌓이는 구간을 스택 프레임이라고 부른다.
Stack Frame
javascript
function sum(a, b) {
const d = a + b;
return d;
}
function main() {
const c = sum(1, 2);
return c;
}
간단한 예시를 들어서 스택 프레임에 대해 알아보자. 참고 자료
 image.png
image.png
우선 main 함수가 호출되었을 때 stack 영역의 상황이다.
맨 아래에는 RET(Return Address) 가 저장이 되는데, 함수가 끝나고나면 돌아갈 위치를 저장하고 있다.
main 함수의 경우는 프로그램의 시작점으로 보이지만 실제로는 Start 라는, main 함수를 호출하는 부분이 존재한다고 한다.
그 위에는 RBP 가 쌓이는데, 이전 함수의 RBP를 저장하고나서 현재 스택 프레임의 시작을 가리키도록 RBP의 값을 바꾼다.
현재 스택 프레임의 시작을 가리키도록 바꿔놨기 때문에 RBP를 기준으로 변수 c를 탐색하거나 하는 등을 할 수 있다.
그 다음에는 지역 변수 c가 쌓인다.
이제 sum 함수의 실행 시점까지 넘어가보자
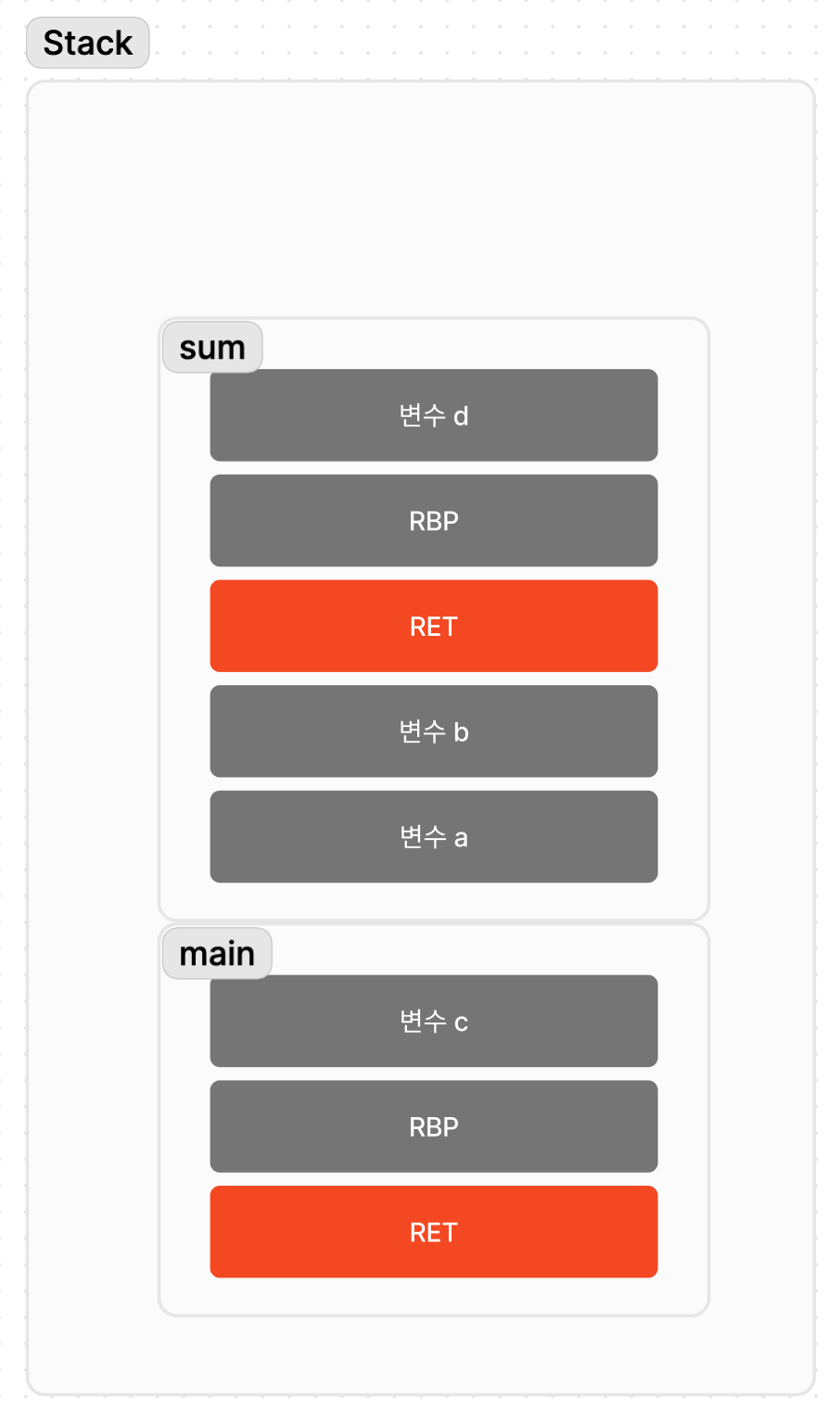 image.png
image.png
매개 변수 a,b 가 먼저 쌓이고 RET, RBP, 지역 변수 d가 쌓인 것을 볼 수 있다.
- 함수를 호출하는 쪽에서 매개 변수를 먼저 스택에 푸시하게 되고,
- 실제로 호출되면서 RET 가 스택에 푸시된다.
- 이전 함수의 RBP를 저장하고, RBP는 현재의 스택 프레임 시작 지점을 가리키도록 바꾼다.
- 지역 변수가 쌓인다.
Day 06 학습 정리
객체지향 프로그래밍
객체지향 프로그래밍은 프로그램을 명령어 또는 함수의 목록으로 보는 전통적인 명령형 프로그래밍의 절차지향적 관점에서 벗어나 여러 개의 독립적 단위, 즉 객체의 집합으로 프로그램을 표현하려는 프로그래밍 패러다임을 말한다. 객체는 다양한 속성들을 가지고, 속성에 대한 값만 다르게 해서 객체들을 생성하고 다른 객체들과 구별할 수 있다. 이처럼 다양한 속성 중에서 프로그램에 필요한 속성만 추려내는 것을 추상화 라고 하며, 우리가 알고 있는 추상클래스도 이렇게 추상화해서 객체들의 공통적인 특징들을 가지고 있는 클래스이다.
클래스
자바스크립트는 프로토타입 기반의 객체지향 언어이고, 클래스 또한 내부적으로는 프로토타입으로 돌아가기 때문에 문법적 설탕 이라는 표현을 쓰고는 한다. 결국 문법이 조금 다르게 보이는, 프로토타입 패턴을 클래스 패턴처럼 사용할 수 있게 해주는 것에 불과하다는 이야기이다. 물론 클래스는 생성자 함수보다 엄격하며 생성자 함수에서는 제공하지 않는 기능도 제공을 한다고는 한다.
문법적 설탕이란 기존의 코드를 조금 더 깔끔하고 가독성 높게 쓰는 방법을 얘기한다.
생성자 함수
생성자 함수란 new 연산자와 함께 호출하여 객체(인스턴스)를 생성하는 함수를 말한다.
javascript
function Character(name) {
this.name = name;
this.setName = function (newName) {
this.name = newName;
};
}
const firstCharacter = new Character("JjangGu");
function 키워드로 만들어진 characters 함수가, new 키워드와 함께 쓰이면 객체를 생성하고, new 키워드 없이 사용되면 그저 함수처럼 작동한다.
자바스크립트의 모든 함수는 객체 이고 call(호출) 할 수 있다. 함수 객체 내부에는 [[Call]], [[Construct]] 와 같은 내부 메소드가 존재한다. new 와 함께 썼을 경우 [[Construct]]메소드가 호출되는 것이다. 그렇다면 모든 함수에 [[Construct]] 메소드가 있는 것일까?
자바스크립트 엔진은 함수를 직접 평가하면서 함수 선언문(function a() {}) , 함수 표현식 (const b = function(){}) , 쿨래스에 한해서 constructor 로 인정하고 나머지의 경우에는 생성자로 인정하지 않는다. 따라서 [[Consturct]] 함수는 constructor 로 인정 받은 함수 객체만이 가지고 있는 것이다.
프로토타입
상속
객체지향 프로그래밍에서는 상속 으로 중복되는 코드를 줄일 수 있다. 상속은 어떤 객체의 property 혹은 method 를 다른 객체가 사용할 수 있는 것을 말한다.
자바스크립트에서는 이 상속을 프로토타입 으로 구현한다.
javascript
function Person(name) {
this.name = name;
}
Person.prototype.type = "mammalia";
Person.prototype.breath = function () {
return "휴 살앗당";
};
인간이라는 객체는 각각 다른 이름을 지닐 수 있지만, 모든 인간 객체는 포유류이며, 숨을 쉬어야한다. 혹시 이 규칙에 위배되는 사람이 있으면 제보를 해주면 감사할 것 같다.
그래서 포유류이고 숨을 쉬는 것은 모든 인간 객체가 중복되어 가지고 있을 것이고 Person 객체의 prototype 에 정의하는 것이다.
캡슐화
캡슐화(capsulation)은 객체의 상태를 나타내는 property 나 method 를 하나로 묶는 것을 말한다. 마치 약 안에 성분이 어떻게 작용하는지는 모르지만, 약의 이름과 효능정도만 알고 먹는다는 느낌이다. 캡슐화를 통해 정보를 은닉하거나, 객체의 상태가 변경되는 것을 막을 수 있다.
다형성
다형성(polymorphism)은 하나의 객체가 여러 가지 형태를 가질 수 있는 능력을 의미한다. 말이 너무 어려운 것 같은데, 인간이라는 객체는 모두 숨을 쉬어야하지만 숨을 얼마나 참을 수 있는지, 심장과 폐가 얼마나 좋은지에 따라서도 조금씩 다른 형태의 숨쉬기 메소드를 가질 것이다. 이렇게 주로 오버로딩 과 오버라이딩 등으로 하나의 객체가 여러 가지 형태를 가질 수 있도록 구현할 수 있다.
출처
모던 자바스크립트 Deep Dive
Day07 학습 정리
자바스크립트 테스트 도구, Jest
설치
Jest 는 간단하게 npm install --save-dev jest 로 설치해서 사용할 수 있다.
설정이 따로 필요 없다고 하는 것 같았지만 테스트를 하기 위한 js 파일에서 ES6 모듈 import 가 되지 않아서 추가 설정을 거쳤다.
babel 이라는 것을 새로 설치해서 config 를 수정해야 #한다고 하는데, babel 이 뭔지는 조금 더 찾아봐야겠다.
Babel 이 뭘까?
Babel 은 트랜스파일러(transpiler) 로, 코드를 변환 하는데 목적이 있다. 그렇다면 갑자기 코드를 왜 변환해야하는걸까?
예를 들어 ES6에서 지원하는 화살표 함수는 구형 브라우저(IE 같은..) 에서는 지원하지 않는 문법일 수도 있다.
따라서 구형 브라우저가 지원하는 문법으로 변환해야할 때가 있고, 이를 위해서 Babel 을 사용하는 것이다.
Jest 는 CommonJS 를 기반으로 동작하기 때문에 ES6 문법인 import, export module 을 이해하지 못한다.
따라서 import, export 부분을 jest 가 이해할 수 있도록 트랜스파일링하는 것이다.
shell
npm install -D jest @types/jest @babel/core @babel/preset-env
bable 을 사용하려면 @babel/preset-env 를 설치해야 한다고 한다. 이는 함께 사용되어야 하는 Babel 플러그인을 모아 둔 것으로, Babel 프리셋이라고 부른다.
Babel이 제공하는 공식 프리셋은 4가지이다.
- @babel/preset-env
- @babel/preset-flow
- @babel/preset-react
- @babel/preset-typescript
이 중에서, preset-env 는 필요한 플러그인들을 프로젝트 지원 환경에 맞추어 동적으로 결정해준다고 한다.
아래처럼 babel config 를 수정하면, @babel/preset-env 를 사용하겠다는 의미이다.
json
/* babel.config.json */
{
"presets": ["@babel/preset-env"]
}
json
/* jest.config.json */
{
"verbose": true,
"collectCoverage": true
}
#
테스트
테스트를 하는 방법은 상당히 간단했는데, test 를 #사용해서 함수를 만든다.
test
javascript
test("two plus two is four", () => {
expect(2 + 2).toBe(4);
});
결과값을 비교하는 Matchers가 여러 개 있는데, toBe, toEqual, toMatch, toThrow 등이 있다고 한다.
- toBe: 참조값이 같은지 확인한다. (내용이 같아도 서로 다른 것을 가리키면 false)
- toEqual: 객체의 값이 같은지 확인한다.
- toMatch: 정규식을 활용해서 문자열 match #- toThrow: 함수가 에러를 발생시키는지 확인한다.
비동기 테스트
비동기 코드는 어떻게 테스트 할 수 있을까 고민이 있었는데 #친절하게도 공식 문서에 잘 정리가 되어 있었다.
assertion
expect.assertions(N)) 은 테스트 중에 정확히 N번 expect 호출을 실행할 것을 요구한다.
예시를 들어서 한 번 봐보자.
우선 doAsync 함수는 callback 함수 2개를 받아서, 비동기적으로 각각의 콜백 함수를 1번씩 실행하는 함수이다.
각각의 callback1, 2 에서는 expect 가 한 번씩 실행된다. 의도대로 잘 흘러간다면 doAsync 를 실행했을 때 expect 가 딱 2번 실행될 것이다.
assertion 은 콜백함수가 정상적으로 실행되는지를 확인하기 좋다.
javascript
test("doAsync calls both callbacks", () => {
expect.assertions(2);
function callback1(data) {
expect(data).toBeTruthy();
}
function callback2(data) {
expect(data).toBeTruthy();
}
doAsync(callback1, callback2);
});
#
Promise
Return a promise from your test, and Jest will wait for that promise to resolve. If the promise is rejected, the test will fail. For example, let’s say that fetchData returns a promise that is supposed to resolve to the string ‘peanut butter’. We could test it with:
Promise 의 경우에는 resolve 되었을 때, test 를 진행하면 된다. reject 의 경우에는 test 가 fail 된다.
javascript
test("the data is peanut butter", () => {
return fetchData().then((data) => {
expect(data).toBe("peanut butter");
});
});
#
Async/Await
async await 을 사용해서 테스트를 하고 싶으면, 콜백 함수 앞에 async 키워드를 사용하면 된다.
javascript
test("the data is peanut butter", async () => {
const data = await fetchData();
expect(data).toBe("peanut butter");
});
test("the fetch fails with an error", async () => {
expect.assertions(1);
try {
await fetchData();
} catch (error) {
expect(error).toMatch("error");
}
});
async 와 await 을 .resolves 와 .rejects 랑 혼합해서 사용할 수도 있다고 한다.
javascript
test("the data is peanut butter", async () => {
await expect(fetchData()).resolves.toBe("peanut butter");
});
test("the fetch fails with an error", async () => {
await expect(fetchData()).rejects.toMatch("error");
});
이렇게 작성하는 것과 위에서 작성한 것과 동일하게 작동하는, 문법적 설탕이라고 한다.
만약 promise 가 reject 되는 것으로 예상한다면, .catch 과 assertion 를 사용하라고 한다.
javascript
test("the fetch fails with an error", () => {
expect.assertions(1);
return fetchData().catch((error) => expect(error).toMatch("error"));
});
#
Callback
Promise 를 사용하지 않는 경우, 콜백을 사용해서 테스트 할 수 있다. 예를 들어, data 에 어떤 작업을 하고나서 콜백함수로 data를 넘겨주는 fetchData 라는 함수가 있다고 하자. 만약 아래와 같이 테스트 코드를 작성하면 어떻게 될까?
javascript
// Don't do this!
test("the data is peanut butter", () => {
function callback(error, data) {
if (error) {
throw error;
}
expect(data).toBe("peanut butter");
}
fetchData(callback);
});
아쉽게도 이 테스트 코드는 의도대로 흘러가지는 않는다. Jest 에서는 코드가 끝나는 순간 테스트를 끝내버린다. 다시 말해서 콜백 함수가 실행되기까지 기다려주는게 아니라, fetchData(callback) 의 실행이 끝나고 테스트가 끝날 수 있다는 얘기다. 그러면 어떻게 코드를 작성해야 콜백 함수를 기다릴 수 있을까?
test에 done 인자를 넣어서 콜백 함수가 끝날때까지 기다릴 수 있다.
javascript
test("the data is peanut butter", (done) => {
function callback(error, data) {
if (error) {
done(error);
return;
}
try {
expect(data).toBe("peanut butter");
done();
} catch (error) {
done(error);
}
}
fetchData(callback);
});
만약 모종의 이유로 done() 이 호출되지 않는다면 테스트는 타임아웃 에러로 실패해버린다.
또한 expect 가 fail 하게 되면, error를 던질 뿐이지 done() 이 호출되지는 않는다. 따라서 왜 실패했는지 로그를 보고 싶다면 try-catch 로 감싸서, catch 구문에도 done(error) 같은 것이 있어야 한다.
만약 테스트 함수에 done() 이 전달되고 동시에 Promise 를 반환하는 경우 오류가 발생한다. 이는 테스트에서 메모리 누수를 방지하기 위한 조치라고 한다.
done() 과 Promise 를 동시에 쓰는 이상한 짓을 하지 #말자.
.resolves / .rejects
.resolves 를 사용하면, promise 가 resolve 될 때까지 대기한다. reject 될 경우에는 테스트에 fail 한다.
javascript
test("the data is peanut butter", () => {
return expect(fetchData()).resolves.toBe("peanut butter");
});
주의해야할 점은, 테스트 함수 내에서 Promise 를 반환하는 경우 return 을 사용하지 않으면 Jest 는 테스트가 끝났다고 판단해버릴 수 있다.
이 경우에는 Promise 가 아직 해결되지 않았음에도 테스트가 끝나기 때문에 의도한 결과가 나오지 않을 수 있다.
.reject 는 resolves 와 반대라고 이해하면 된다. fulfilled 될 경우에는 테스트에 fail 한다.
Day 08 학습 정리
함수형 프로그래밍
함수형 프로그래밍을 왜 사용하는 것일까?
기본적으로 절차지향적, 객체지향적 프로그래밍은 상태 라는 것을 갖는다. 우리가 자주 사용하는 변수들이 이러한 상태의 대표적인 예시이다.
javascript
function sum(a, b){
return a + b;
}
class GameCharacter {
...
#HP = 500;
getDamaged(damage){
// 현재 HP 에서 damage 만큼 을 뺀, HP를 반환한다.
}
}
sum(a, b) 함수의 경우 어느 시점에 (a,b) 를 넣어도 (a, b)가 이전에 넣었던 (a, b) 와 동일하다면 결과 값이 다를 리가 없다. 결과값인 a + b 에 영향을 미칠 상태 같은 것이 없다.
반면 GameCharacter 는 HP 라는 상태를 가지고 있다. HP 상태에 따라 getDamaged(damage) 함수는 다른 결과 값(남은 HP)을 반환할 것이다.
변수를 개발자가 직접 다루게 되는 것을 최소화하는게 함수형 프로그래밍
함수형 프로그래밍은 이런 상태를 최소화 하는데 목적이 있다. 변수(상태)가 많다는 것은 버그나 문제가 일어날 가능성이 높아질 수 밖에 없다는걸 의미한다.
함수가 일급 객체(First-Class Objects)인가? 일급 객체는 숫자 등의 일반직언 다른 데이터처럼 다뤄질 수 있다.
변수에 할당되거나, 함수에 인자로 넘겨지거나, 반환 값으로 나오거나, 익명으로 만들어지는 등이 가능하다.
함수형 프로그래밍의 장점과 단점은 무엇일까?
함수형 프로그래밍의 특징
순수성
함수에서 외부의 상태값을 참조하거나, 외부의 상태를 바꾸는 것은 순수성이 아니다. 동일한 인자를 넣었을 때 항상 동일한 결과를 반환하고, 언제 선언이 되었는지 외부에 전혀 영향이 받지 않도록 해야함
불변성
함수의 인자로 넘겨진 데이터를 변경하는것은 함수형이 아니고, 새로운 오브젝트를 만들어서 결과값으로 전달해야한다.
-
side effect 가 없음 -> Object freeze
Expression
조건문같은 여러가지 문장을 사용하는건 함수형 프로그래밍이 아니다. for loop 를 이용해서 배열을 하나씩 돌면 안되고, 고차함수 활용 -> 이건 이유가 뭐지?
일급 객체
함수를 파라미터로 넘기거나, 함수에서 또다른 함수를 리턴하는 고차함수 속성을 가지고 있어야 한다.
팩토리 패턴을 쓰면 클래스를 만들 때 궁금증 순수 함수 및 객체 생성 과정을 캡슐화 할 수 있다.
연결리스트를 쓰면서, 연결리스트의 노드에는 변경을 가하지 않고, 연결된 선만 수정해서 반환?
- 불변성을 유지하기 위해 인스턴스를 복사해서, 인스턴스에 변경을 가하고 반환하면 시간이 오래 걸리지 않는건가??
Day 09 학습 정리
Promise
약속이라는 뜻의 키워드를 가지게 된 이유가 뭘까? 당장 결과를 알기는 힘들지만, 미래에 결과를 주기로 약속하는 개념으로 이해하면 쉽다.
보통 비동기 작업을 처리하는데 사용하는 객체 이다.
javascript
const promise = new Promise(() => {
//callback
});
promise
.then((response) => {
console.log(response);
return response.data;
})
.catch((reason) => {
console.log(reason);
})
.then((data) => {
console.log(data);
});
콜백 함수로 넘어온 함수를, 비동기로 작업하는동안 promise 객체는 Pending 상태이고,
비동기 작업(콜백 함수)가 완료되면 then 메소드로, 실패하면 catch 메소드로 결과를 받을 수 있다.
promise 의 then 함수는 작업이 완료되고 넘어온 결과값을 첫 인자로 전달받게 되는데, 무엇인가를 반환(return) 하려고 하면 또 다시 Promise 로 감싸서(Promise 객체로 감싸서) 내보낸다.
그런데 이 작업, 어디서 많이 본 작업인 것 같다.
Promise 의 then 은 flatmap 의 역할을 한다고 볼 수 있어, monadic 하다고 할 수 있고 이러한 이유 때문에 콜백지옥(콜백이 중첩으로 쌓여가는)을 피할 수 있다.
day 11-12 학습 정리
Array.from
우선 Array.from 은 생성자가 아님을 유의해야한다. static 메소드이므로 new 키워드와 함께 사용하지 않는다.
text
Array.from(arrayLike)
Array.from(arrayLike, mapFn)
Array.from(arrayLike, mapFn, thisArg)
Array.from 메소드는 유사 배열 객체 혹은 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환한다.
javascript
Array.from("HELLOWORLD"); // ['H', 'E', 'L', 'L', 'O', 'W', 'O', 'R', 'L', 'D'];
//문자열은 이터러블 객체이다.
Array.from(arrayLike, mapFn) 은 이터러블 객체(arrayLike)를 순회하며 모든 요소에 대해 호출하는 map 함수를 2번째 인자로 넣을 수 있다. 이 mapFn 의 반환값이 대신 배열에 추가가 된다.
javascript
// arrayLike -> {length : 3}, Length만 있으므로 undefined 3개가 요소를 채우게 된다. [undefined, undefined, undefined]
Array.from({ length: 3 });
Array.from({ length: 3 }, (element, index) => {
// element : 배열에서 처리 중인 요소
// index : 현재 인덱스
return new Array();
});
Promise 와 클로저
Promise 함수를 작성하면서 변수를 하나 선언해서 아래와 같이 사용을 했다.
text
const saveNumber = 10;
new Promise((resolve, reject) => {
return resolve(50)
}).then((result) =>
console.log(`${result - saveNumber}`));
Promise 의 결과 값에서 saveNumber 만큼을 뺀, 결과 값을 출력하는 promise 이다.
그런데 여기서 Promise 가 제대로 작동하려면 saveNumber 가 존재해야하는(상태가 유지되어야하는) 상황이다.
결국 클로저와 유사하게 코드를 짠 것이였는데 Promise 는 비동기로 작동하기 때문에 saveNumber 의 라이프 사이클이 기존의 클로저와 유사한지 고민이 되었다. 결론은 Promise 에서도 클로저가 잘 동작한다!
구조 분해 할당과 … rest 문법
javascript
const [a, b] = [s.split(",")[0], s.split(",").slice(1)];
위와 같은 코드를 작성하고 있었다. split 한 결과의 첫 번째 원소만 a에, 나머지는 b에 할당하고 싶었다.
여기서 훨씬 깔끔하게 작성하는 방법이 있는데, rest 문법을 사용하는 것이다.
javascript
const [a, ...b] = s.split(",");
훨씬 간단하다..!
스프레드 문법과 rest 문법
스프레드 문법(…) 은 하나로 뭉쳐 있는 여러 값들의 집합을 펼쳐서 개별적인 값들의 목록으로 만든다.
스프레드 문법은 이터러블에 한해서 사용 가능하고 스프레드 문법의 결과는 값이 아니다.
Rest 문법은 스프레드 문법과 반대라고 생각하면 된다.
rest 문법은 여러 목록들을 배열로 전달받는 방법이다.
자바스크립트에서 interface, duck typing
자바스크립트는 공식적으로 interface 를 지원하지는 않는다. 타입스크립트로 넘어가게 되면 지원하는데, 자바스크립트에서 지원되지 않는 이유가 궁금해서 찾아봤더니
Interfaces don’t exist in JavaScript because it is a dynamic language, where types are changed so often that the developer may not have even realised.
라고 한다. 자바스크립트는 동적 언어라서 개발자가 모르는 사이에 타입이 바뀌는 경우가 종종 있으니 인터페이스가 없다는 것이다.
그래서 비슷한 방법이라도 있을까? 찾아보면서 동적 타입 언어에서 활용할 수 있을 법한, duck typing 이라는 개념이 있다는 걸 알게 되었다.
duck typing : 날 수 있고, 두 발로 걷고, 소리를 낸다 (-> 메소드들) 라는 메소드를 가지고 있는 무언가를 duck 이라고 가정한다면, 닭도 duck 타입이라고 할 수 있다. 라는 의미이다.
예를 들어,
javascript
const DuckTyping = {
WalkingOnTwoFeet : (duckType) => duckType.WalkingOnTwoFeet(),
MakeASound : (duckType) => duckType.MakeASound(),
Flying : (duckType) => duckType.Flying(),
}
class RealDuck {
WalkingOnTwoFeet(){
console.log("오리가 두 발로 걷는다.");
}
MakeASound(){
console.log("꽥꽥");
}
Flying(){
console.log("오리가 난다");
}
}
class Chicken{
WalkingOnTwoFeet(){
console.log("닭이 두 발로 걷는다.");
}
MakeASound(){
console.log("꼬끼오");
}
Flying(){
console.log("닭이 난다.");
}
IamAChicken(){
console.log("나는 닭입니다.")
}
}
const realDuck = new RealDuck();
const chicken = new Chicken();
DuckTyping.MakeASound(realDuck);
DuckTyping.MakeASound(chicken);
위의 코드는 닭과 오리를 클래스로 만든 코드이다. 다만 실제로 닭과 오리가 같지는 않으나 하는 행동(메소드)는 비슷하게 보이기도 한다. 이제 DuckTyping 객체에 있는 함수들에 realDuck 객체와 chicken 객체를 넘겨줘서 실행해보면, 둘의 행동에 작은 차이가 있긴 하지만(꽥꽥/꼬끼오 같은) 실제로 두 행동(MakeASound)이 실행은 된다. 닭이 오리와 같은 행동을 수행할 수 있으므로, 닭은 오리 타입이라고 인정하겠다는 것이다.
Day 13 학습 정리
EventEmitter 와 Promise 는 각각 어떨 때 쓰는 걸까?
이번에 fs 의 Stream 을 사용해서 파일을 읽어오고 있었는데, 비동기 함수로 동작한다는 걸 직접 코드를 굴려보며 깨달았다.
찾아보니, Stream 은 전부 EventEmitter 의 인스턴스였다. 그렇다보니 on 같은 메소드로 이벤트를 등록하고 관리해야하는 것이였다. 여기서 살짝 이해가 되지 않는 부분이 있었는데, Promise는 어떤 비동기 작업의 성공/실패에 따른 핸들러를, EventEmitter 는 다양한 이벤트에 따른 다양한 핸들러를 사용하는 차이점이 있다고 이해했는데 파일을 읽을 때, 읽기 성공/실패 말고 다른 이벤트들이 많이 있다는건가? 라는 생각을 하게 되었다. 그래서 찾아보니 데이터를 읽을 때 data 이벤트가, 전부 다 읽었을 때 end 이벤트가 발생하는 등, 다양한 이벤트들이 존재하는 것 같았다.
All objects that emit events are instances of the EventEmitter class. 라는 구문으로 보아 그냥 이벤트와 관련 있으면 무조건 공식문서를 보고 EventEmitter 의 인스턴스인지 확인해보는 것이 좋겠다.
다만 공식문서를 살펴보니 Promise로 구성된 Stream 도 있는걸 알 수 있었다.
Streams Promises API##
Added in: v15.0.0
The stream/promises API provides an alternative set of asynchronous utility functions for streams that return Promise objects rather than using callbacks. The API is accessible via require('node:stream/promises') or require('node:stream').promises.
EventEmitter 를 조금 더 파헤쳐보자
EventEmitter 가 이벤트를 emit 할 땐, 등록된 순서에 맞게 동기적으로 호출한다.
Synchronously calls each of the listeners registered for the event named eventName, in the order they were registered, passing the supplied arguments to each.
Event 를 리스너 배열의 맨 앞에 추가하고 싶다면
Event 는 원래 리스너 배열의 맨 마지막에 추가가 되고, 위에서 말한 것처럼 동기적으로 호출하는데 만약 이벤트를 리스너 배열의 맨 앞에 추가하고 싶다면 prependListener() 메소드를 사용하자.
EventEmitter 는 중복 검사를 하지 않는다.
만약 똑같은 이벤트에 해당하는 똑같은 핸들러함수를 여러번 생성한다면, 이미 존재하는 리스너(핸들러) 입니다 라고 오류를 뱉는게 아니라 그냥 여러 번의 리스너가 추가 된다.
그러다가 리스너를 지우고 싶어서 removeListener(eventName, listener) 를 활용해서 지우려고 시도한다면, 여러 번 추가한 만큼 여러 번 삭제해야한다. removeListener 는 오직 1개의 리스너 인스턴스를 지운다.
마찬가지로 이벤트가 emit 되면 여러 번 등록했던 리스너는 1번만 호출되는게 아니라 등록한만큼 호출된다.
EventEmitter 에서 이벤트를 emit 하고 바로 리스너를 지워도, 리스너(핸들러)는 실행되고나서 지워진다.
javascript
const EventEmitter = require("node:events");
class MyEmitter extends EventEmitter {}
const myEmitter = new MyEmitter();
const callbackA = () => {
console.log("A");
myEmitter.removeListener("event", callbackB);
};
const callbackB = () => {
console.log("B");
};
myEmitter.on("event", callbackA);
myEmitter.on("event", callbackB);
// callbackA removes listener callbackB but it will still be called.
// Internal listener array at time of emit [callbackA, callbackB]
myEmitter.emit("event");
// Prints:
// A
// B
// callbackB is now removed.
// Internal listener array [callbackA]
myEmitter.emit("event");
// Prints:
// A
위의 코드처럼, 콜백A가 실행되면 콜백B는 eventEmitter 에서 삭제된다. 배열의 초반부를 하나씩 순회를 돌고 있는데 누군가 배열의 맨 마지막 원소를 지워버리면 배열의 마지막 원소는 당연히 순회되지 않는 것과 달리 EventEmitter 는 리스너 배열을 복사해서 emit 하기 때문에 콜백B가 호출되기전에 eventEmitter 의 배열에서 삭제되어도, 복사본으로 순회하기 때문에 영향을 미치지 않는다.
Promise 가 reject 될 때, eventEmitter 가 이벤트를 발생할 수 있게 만들기
javascript
const EventEmitter = require("events");
class MyEmitter extends EventEmitter {
constructor(options) {
super({ captureRejections: true });
}
}
const emitter = new MyEmitter();
// 이벤트 리스너로 프로미스를 반환
emitter.on("event", async () => {
throw new Error("Oops!");
});
emitter.on("error", (err) => {
console.log("Captured:", err.message);
});
emitter.emit("event");
사실 EventEmitter 와 Promise 는 하는 일이 어느정도 겹치지만 완전히 다른 영역에 존재한다고 생각했다. 하지만 공식문서를 읽어보니, Promise 가 error 를 만났을 때, 핸들링 되지 않는 에러라면 문제가 발생할 수 있어, Promise 의 reject 를 마치 EventEmitter 에 on 할 수 있는 느낌이다. 위의 코드처럼 captureRejections 를 true 로 설정하면, Promise 의 Reject 를 추적한다.
Git 내부 동작 방식
Git pull? Git fetch?
그동안 remote repo 에서 코드를 가져올 때, 별 생각 없이 git pull 을 먼저 실행했고 rebase 와 merge 가 다르다는 것만 알고있지 어떻게 다른지는 알지 못했다. 그래서 이번 기회에 한 번 정리를 해보려고 한다.
git pull = git fetch + git merge
내가 자주 사용하던 git pull은 git fetch 후에 git merge 하는 과정을 하나의 명령어로 압축시킨 것이다.
따라서 git pull 을 입력하면 git fetch 와 git merge 두 가지의 명령어를 입력한 것과 동일한 결과를 낳는다.
fetch 는 변경점만을 가지고 오는 명령어이다.
git merge? git rebase?
A라는 브랜치의 현재까지의 커밋을 B라는 브랜치에 적용시키려면 당연하게도 커밋을 합쳐서 코드를 합치는 과정을 거쳐야 한다.
이 방법에는 git merge 와 git rebase 두 가지가 있다.
git merge
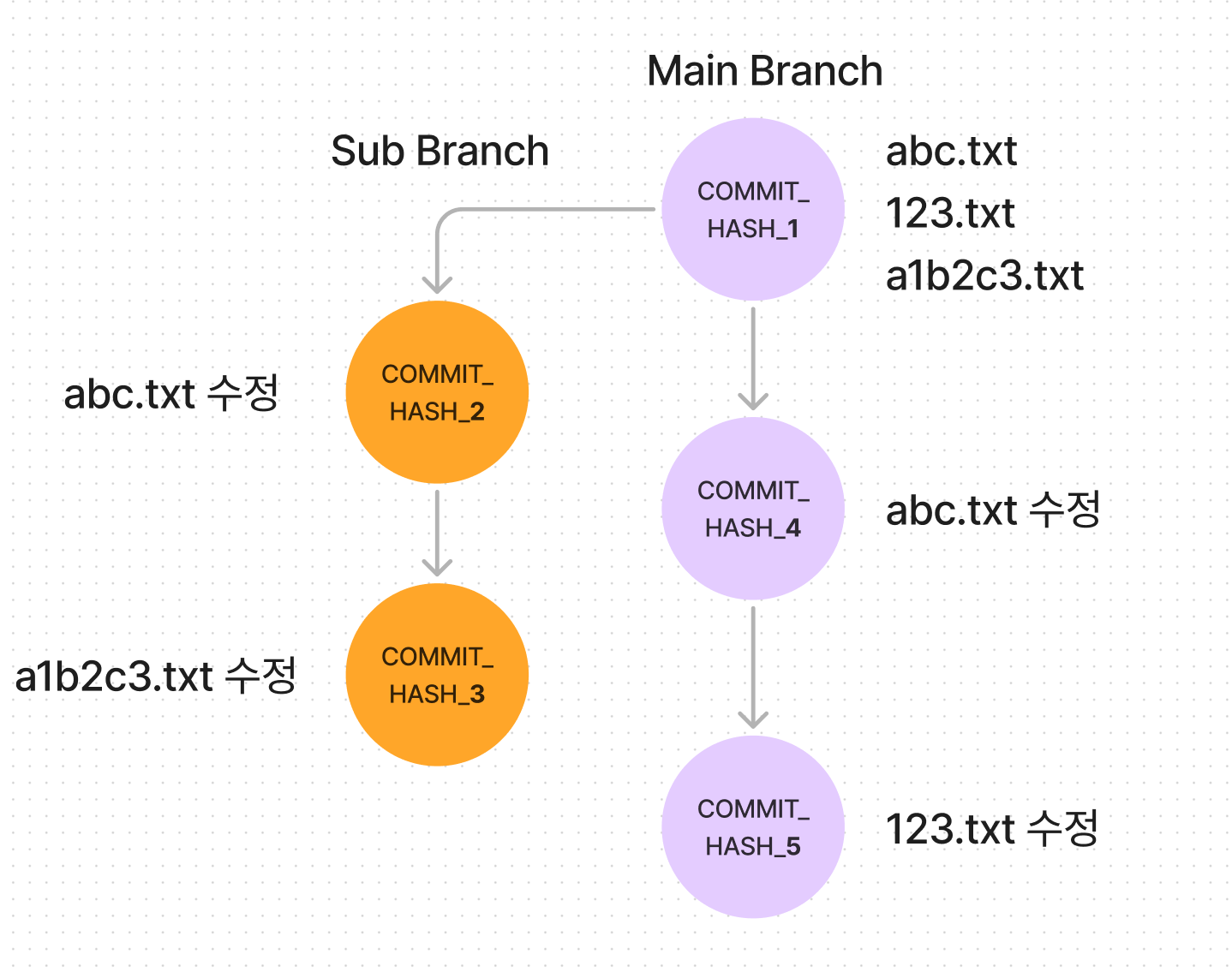 image.png
image.png
위의 그림을 예시로 들어보자.
merge 는 3-way-merge 라는 방식으로 진행되는데, 왜 3-way 냐면, COMMIT_HASH_3 과 COMMIT_HASH_5 만 비교하는게 아니라, 두 커밋의 공통 부모 노드인 COMMIT_HASH_1도 같이 비교하기 때문이다.
COMMIT_HASH_3과 5 중에서 어떤 커밋을 남겨야할지 결정하려면 두 커밋의 공통 부모 노드인 COMMIT_HASH_1 이 기준이 되어야하기 때문이다.
만약 기준점이 없다면 두 커밋 중에서 무엇이 수정된 파일이고 무엇이 수정되지 않은 파일인지 알 수 있을까?
다른 커밋을 다 제외하고 COMMIT_HASH_2의 abc.txt 파일만을 열어서 내용을 읽어봤을 때 이 파일이 이전 커밋으로부터 수정되었는지 안되었는지 알 수 없을 것이다.
이전 커밋의 abc.txt 값을 알아야 바뀌었는지 그대로인지 알 수 있으니까!
그래서 기준점 이 있어야 수정되었는지 그대로인지를 알 수 있다.
아무튼 이렇게 공통 부모 노드를 기준으로 COMMIT_HASH_3 과 COMMIT_HASH_5를 비교해보면,
abc.txt 는 COMMIT_HASH_3 에서도 수정되었고, COMMIT_HASH_5 에서도 수정 되었다 => ** conflict **
a1b2c3.txt 는 COMMIT_HASH_3 에서는 수정되었고, COMMIT_HASH_5 에서는 그대로이다. => COMMIT_HASH_3 수정사항 선택
123.txt 는 COMMIT_HASH_3 에서는 그대로이고, COMMIT_HASH_5 에서는 수정되었다. => COMMIT_HASH_5 수정사항 선택
이렇게 확인할 수 있다. Conflict 가 발생한 abc.txt 파일에 대해서는 사람이 직접 선택해주면 된다.
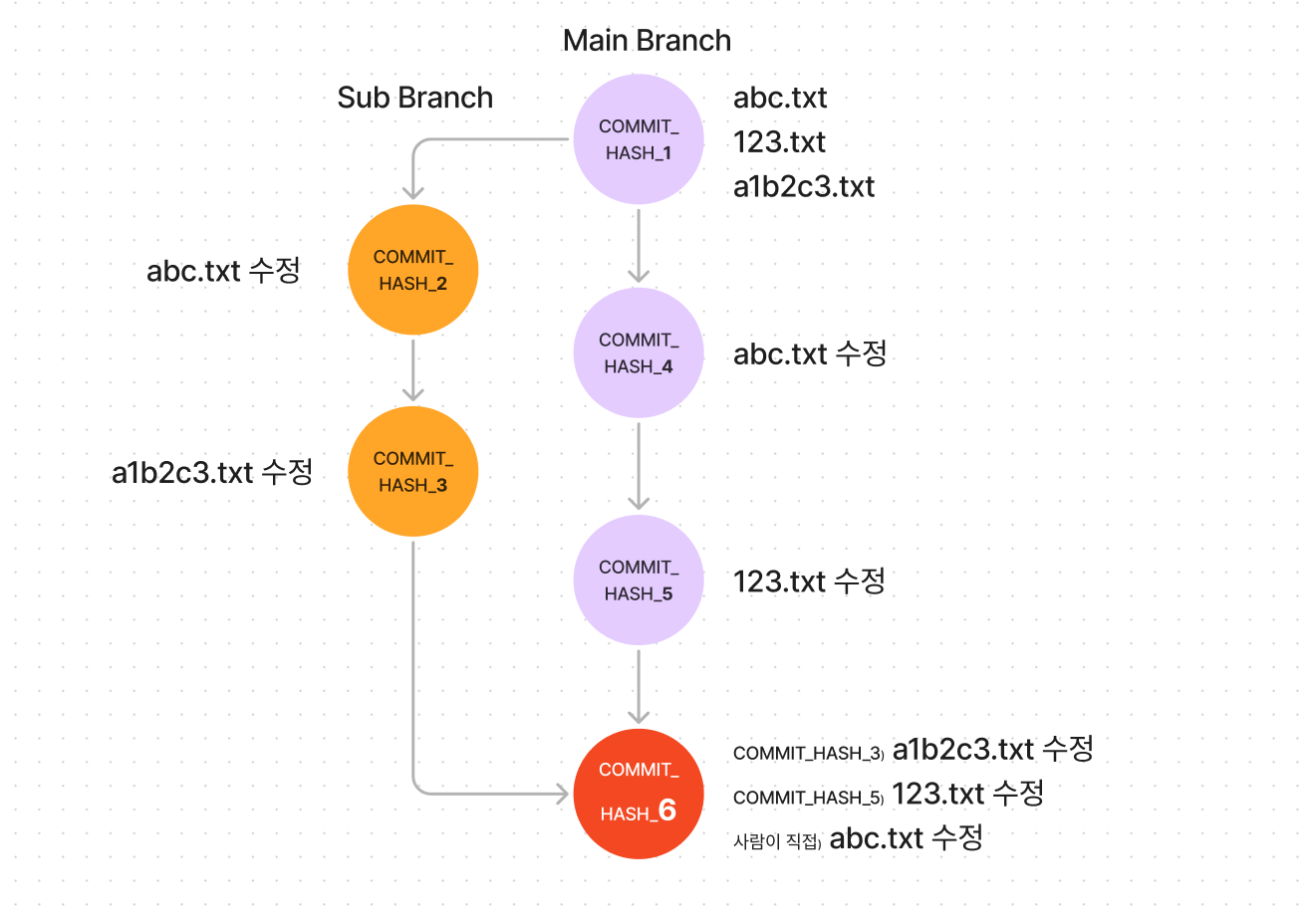 image.png
image.png
git rebase
그렇다면 rebase는 어떻게 다를까? 그리고 사람들은 왜 rebase 를 쓰지 않는걸 권장하는 걸까?
다시 아까의 그림으로 돌아가보자.
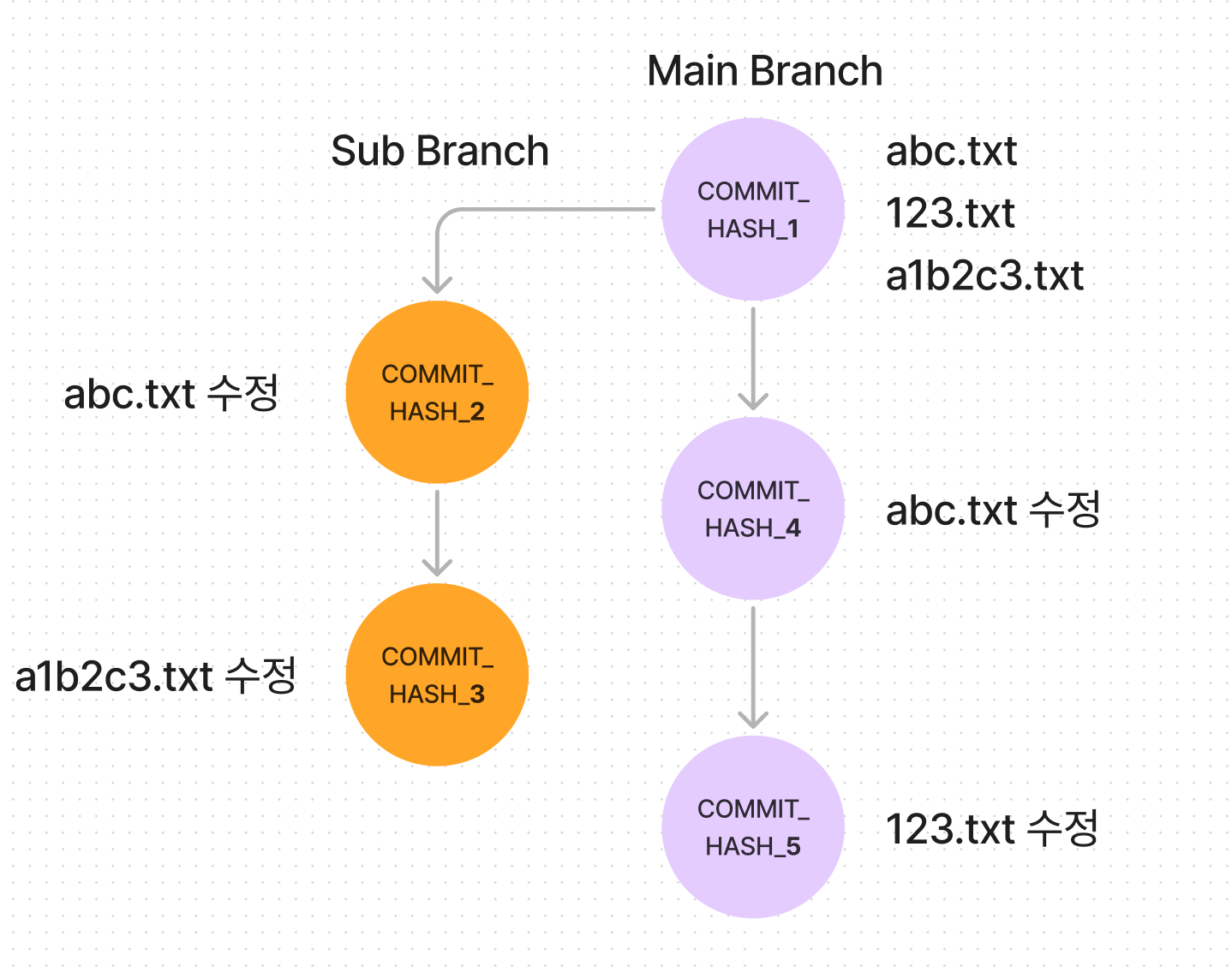 image.png
image.png
이번에도 마찬가지로 abc.txt 는 conflict 가 날 것이다. 그래서 직접 사람의 손으로 수정을 해주는 것 까지는 똑같은데, 결과는 어떨까?
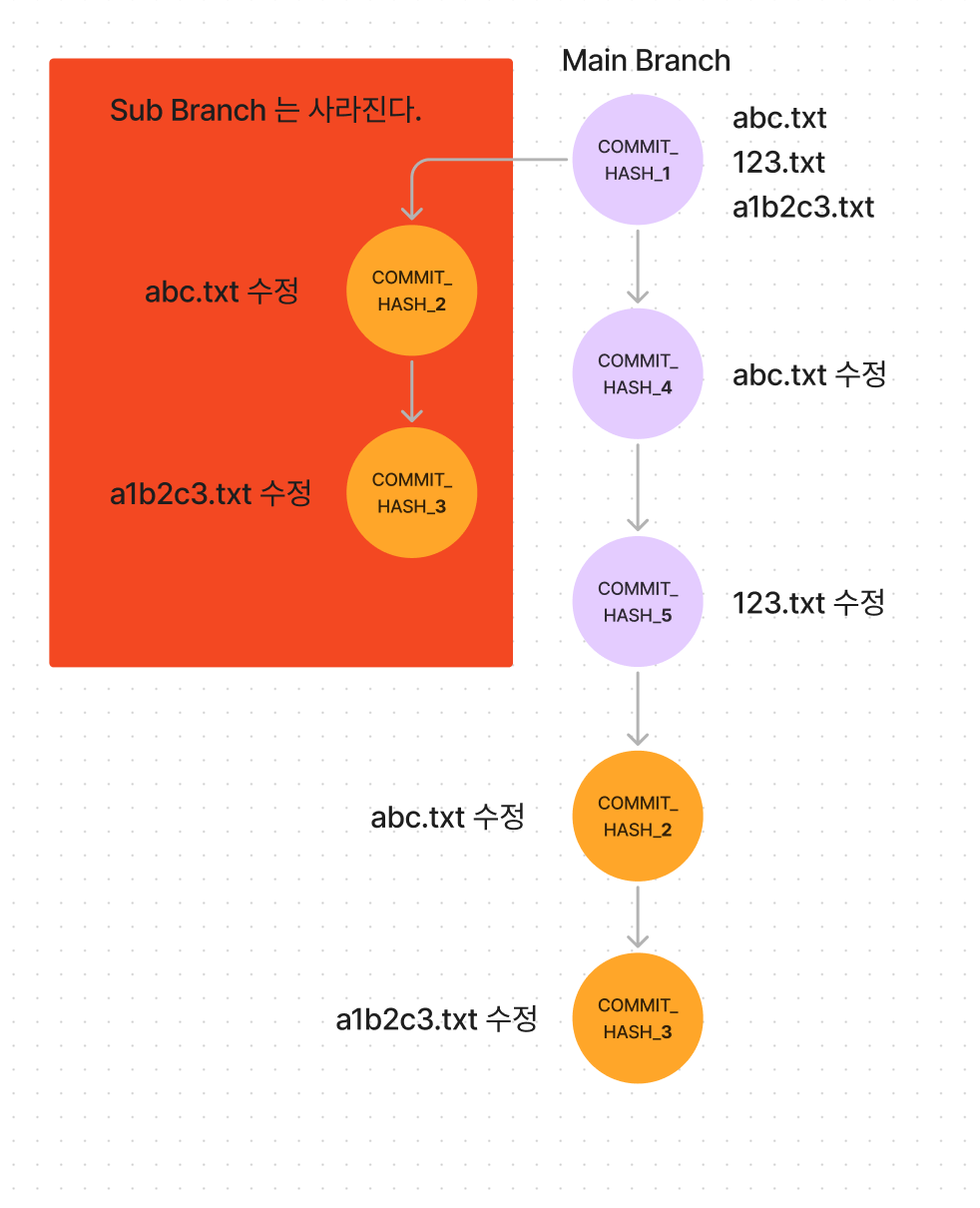 image.png
image.png
rebase 의 결과는 merge 와 다소 다르다.
merge는 하나로 합쳐진 반면, rebase 는 Sub branch 에 있던 commit 들이 Main 브랜치의 뒤에 달라 붙은 결과가 되었다.
우리는 분명 COMMIT_HASH_1 을 기준(base) 로 파일을 비교했는데 COMMIT_HASH_5(new base) 의 뒤에 Sub branch를 추가한 것 같은 그림이다.
rebase 는 심지어 cherry pick 이 가능한데 무슨 의미냐하면 sub branch에서 COMMIT_HASH_2는 숨기고 COMMIT_HASH_3 만 new base에 붙이는 것이 가능하다는 것이다.
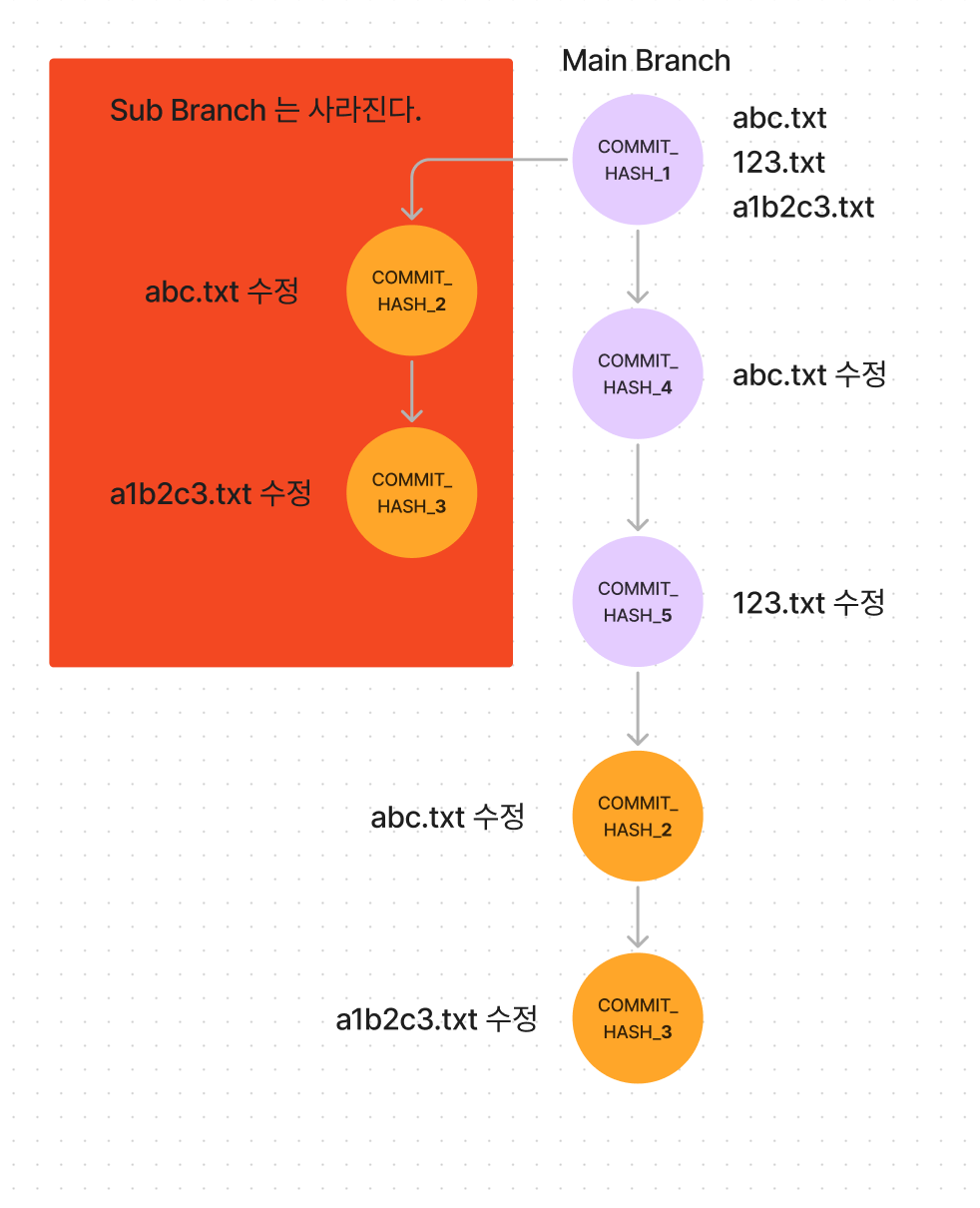 image.png
image.png
rebase 의 문제점?
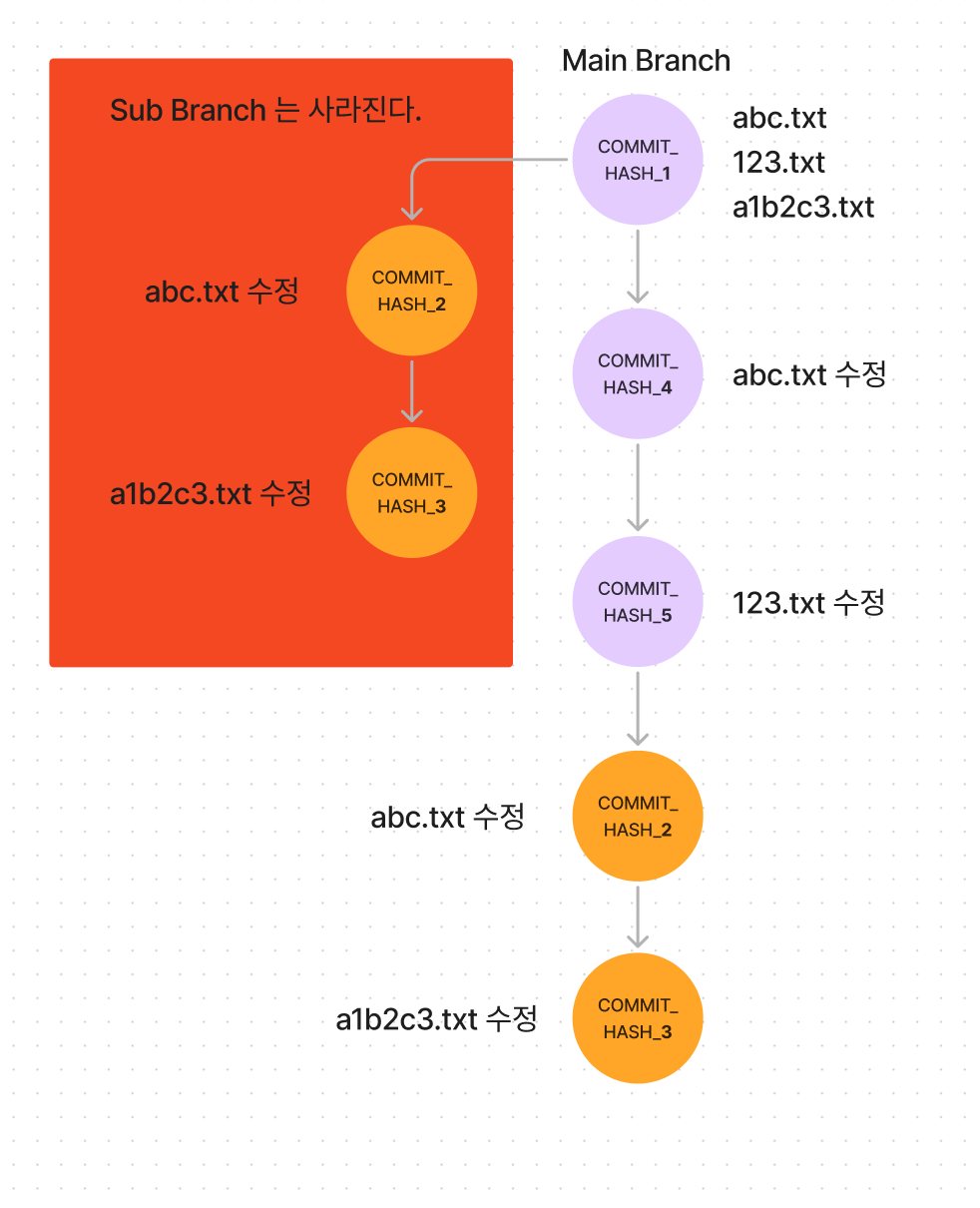 image.png
image.png
위의 그림처럼, sub branch 를 3개를 만들고 각각 회색 영역의 커밋이 초기 커밋이었다고 가정해보자.
세 가지의 sub branch 를 열심히 개발한다음에 하나로 합쳐가지고 Main branch 에 Merge 를 하려고 한다.
git pull 을 해서 하나로 합치고, git rebase 를 써서 합친 뒤에 마지막으로 Main Branch 에 Merge 를 하니까,
노란색 배경의 커밋은 커밋 Hash 값은 다르지만 내용은 같은 커밋인데 Main Branch 에 2개나 생성된 모습을 볼 수 있다.
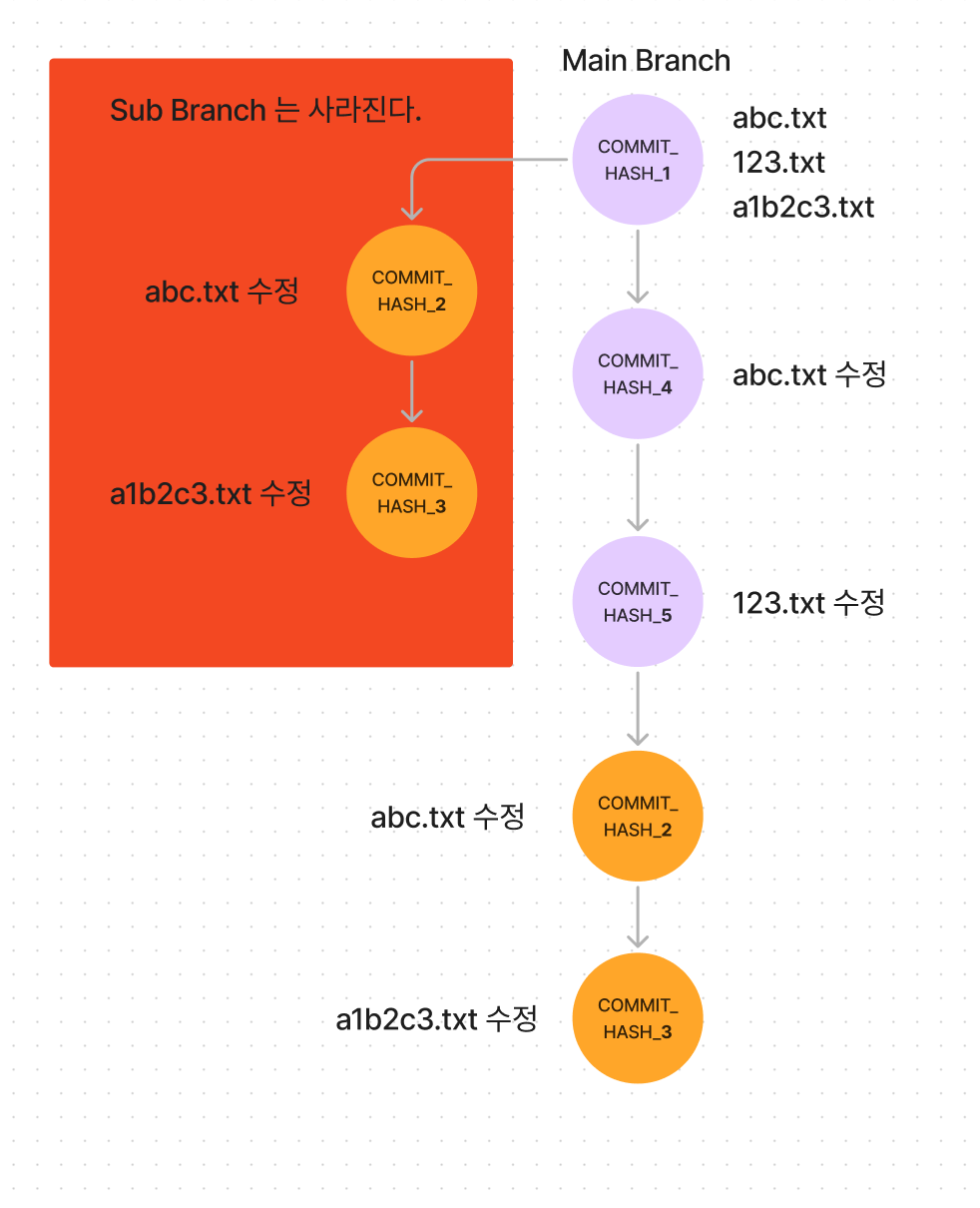 image.png
image.png
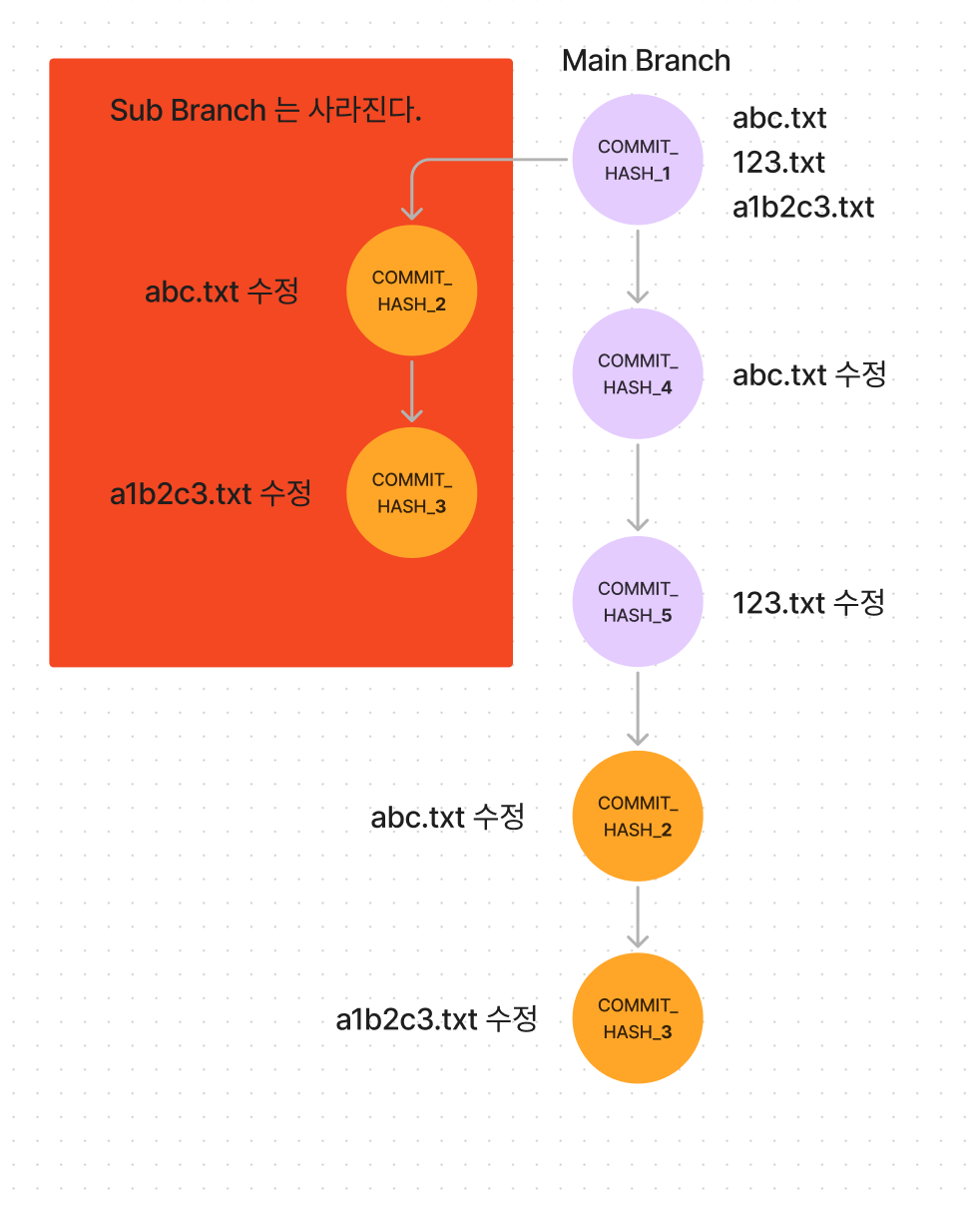 image.png
image.png
Hash? SHA-256?
SHA-256 알고리즘
위의 유튜브 영상에서 설명하는 과정 중에서, 헷갈리거나 설명이 생략되어 있는 부분을 위주로 작성하려고 한다.
“RedBlockBlue” 라는 예시 input 을 256비트로 바꾸기까지의 과정
Preprocess
- “RedBlockBlue” 를 ASCII 코드(각 8bit)로 변환한다. (예시인 “RedBlockBlue” 는 총 96bits (12글자 * 8bit)
- 총 비트 수를 512의 배수가 되게끔 padding 을 추가한다. 현재는 96bit 이기 때문에 512bit 가 되게끔 아래의 방법으로 padding 을 추가한다.
- 맨 뒤에 ‘1’ 을 추가한다.
- (512에 가장 가까운 배수 - 64)bit 가 되기 위한 나머지 비트들은 전부 0으로 채운다.
- 64bit 를 남겨두는 이유는, 64비트에는 입력값(“RedBlockBlue”) 의 길이(96bit)를 이진수로 채운다.
-
 image.png
image.png
- 패딩처리한 비트를 512bit 블록으로 나누어야한다. 예를 들어 패딩 처리한 bit 가 1024 bit 라면 2개의 블록으로, 현재 예시는 512bit 이므로 1개의 블록을 그대로 쓰면 된다.
- 블록마다 한 줄에 32bit 가 되게끔 16개의 줄로 나눈다. (1 개의 block = 512bit 이므로, 512 / 32 = 16줄) 위의 예시 이미지에서 이미 32bit 가 되게끔 한 줄로 나누어서 표현했기 때문에, 해당 이미지를 참조.
Hash Value
이제 초기값이라고 부를 H0 ~ H7 까지, 8개의 32bit Hash 값을 정할 차례이다.
이 H0 ~ H7 에 어떠한 작업을 지속적으로 하면서, 마지막에 병합을 하게 된다면 우리가 원하는 256비트의 출력값이 된다.
그렇다면 초기값을 구하는 방법은 뭘까?
These words were obtained by taking the first thirty-two bits of the fractional parts of the square roots of the first eight prime numbers.
처음 소수는 2 이므로, 2의 제곱근은 1.4142… 이므로 소수점 이하 부분(0.4142…) 만 가져와서 32비트 값으로 변환한다.
Bitwise Addition Modulo 2:
“Bitwise addition modulo 2”는 이진수 덧셈에서 자리올림(carry)을 고려하지 않고 단순히 XOR 연산으로 수행한다.
ROTR, SHR
ROTRy은 y칸씩 오른쪽으로 Shift 하되, 더이상 Shift 할 곳이 없으면 앞으로 돌아오는 과정이다. (순환하는 것 처럼)
SHRy은 똑같이 y칸씩 오른쪽으로 shift 하되, 맨 처음 y칸을 전부 다 0으로 만들어버린다. (더이상 shift 할 곳이 없으면 마치 절벽에서 밀어버리는 것 처럼 0이 되어버린다.)
Sigma Function
첫 번째 사진의 σ0, σ1 는 소문자(lowercase) 시그마 라고 불리고,
두 번째 사진의 Σ0, Σ1은 대문자(uppercase) 시그마 라고 불린다.
⋙ 는 ROTR, ≫ 는 SHR 이고, ⊕ 는 Bitwise Addition Modulo 2 이다.
σ0(x)=(x⋙7)⊕(x⋙18)⊕(x≫3)
σ<sub>1</sub>(x)=(x⋙17)⊕(x⋙19)⊕(x≫10)
Σ0(x)=(x⋙2)⊕(x⋙13)⊕(x⋙22)
Σ<sub>1</sub>(x)=(x⋙6)⊕(x⋙11)⊕(x⋙25)
 image.png
image.png
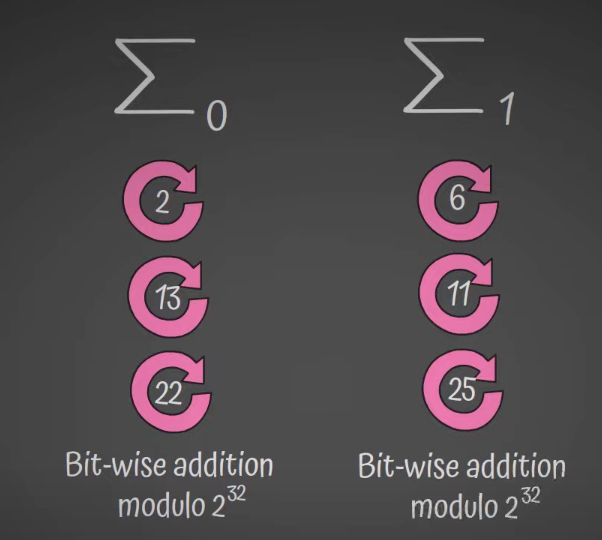 image.png
image.png
Ch function
Ch(e,f,g) 라는 함수가 나오는데 설명을 들어보니 Choose 의 ‘Ch’ 인가? 라는 생각이 들었다.
Ch(e,f,g) 함수는 ‘e’ 를 기준으로 f 를 선택할 지, g 를 선택할 지 결정하는 함수이다. 간단하게 예를 들어,
e = 01010001
f = 10011011
g = 00011111
가 있을 때, e가 0이면 g를, e가 1이면 f를 선택하는 것이다. Ch 함수의 결과값을 r 이라고 할 때,
r[i] = e[i] === 0 ? g[i] : f[i] 함수라고 생각하면 될 것 같다.
비트 연산으로만 작성 한다면 아래와 같이 작성할 수 있다.
javascript
const choose = (x, y, z) => (x & y) ^ (~x & z);
// const choose = (x, y, z) => (x & y) | (~x & z);
/* x가 1이면 y 의 값을 가져오고, x가 0이면 z의 값을 가져온다.
x가 0이면 앞의 x & y 는 무조건 0이고, x 가 1이면 뒤의 ~x & z 는 무조건 0이다.
따라서 두 연산중에 하나는 무조건 0이고, 남은 연산에서 값을 취해오면 된다.
남은 연산에서 값을 취해올 때는 or, xor 상관없이 가져올 수 있다. 따라서 ^ 연산이 아니라 | 연산이여도 상관 없다.
*/
// ^ 연산자는 XOR 연산자이다.
// ~ 연산자는 비트 반전 연산자이다.
const x = 0b10101010101010101010101010101010;
const y = 0b11001100110011001100110011001100;
const z = 0b11110000111100001111000011110000;
const result = choose(x, y, z);
console.log(`Choose(x, y, z) result: ${result.toString(2).padStart(32, "0")}`);
Maj function
Maj(a,b,c) 함수는 Majority 함수라고 하는데, 이 함수도 상당히 간단하다.
그냥 0이 많은지 1이 많은지, 어떤 숫자가 더 많은지 보면 되는 함수이다.
e = 01010001
f = 10011011
g = 00011111
Maj 함수의 결과값을 r 이라고 할 때,
r[i] = e[i]+f[i]+g[i] > 1 ? 1 : 0 이라고 생각하면 되겠다.
(e[i] + f[i] + g[i] === 1의 갯수 이므로)
비트 연산으로 작성한다면 아래와 같이 작성 가능하다.
javascript
const majority = (x, y, z) => (x & y) ^ (x & z) ^ (y & z);
const x = 0b10101010101010101010101010101010;
const y = 0b11001100110011001100110011001100;
const z = 0b11110000111100001111000011110000;
const result = choose(x, y, z);
console.log(`Choose(x, y, z) result: ${result.toString(2).padStart(32, "0")}`);
Pipe
Day02 에서도 한 번 스쳐지나갔던 Pipe 를 함수형 프로그래밍을 공부하며 다시 한 번 보고, 이번에 또 보게 되었다.
Pipe의 개념은 마치 통로로 연결하는 느낌과 비슷하다. 이전의 출력값을 다음 함수의 입력값으로 넘겨주는걸 반복하는, 마치 출구와 입구가 파이프로 이어져있는 것 같은 느낌으로 보면 될 것 같다.
자바스크립트에서는 따로 Pipe 커맨드는 없지만 구현을 할 수는 있다.
javascript
function pipe(...funcList) {
// Rest 파라미터를 사용해서, 실행할 함수들의 배열을 func 에 저장한다.
return (firstFuncArg) => {
funcList.reduce((prevFuncReturn, nextFunc) => {
return nextFunc(prevFuncReturn);
}, firstFuncArg);
};
}
pipe(func1, func2, func3, func4)("firstFunctionArg");
const pipeline = pipe(func1, func2, func3, func4);
pipeline("firstFunctionArg");
먼저 pipe 함수는 funcList 파라미터로 몇 개의 함수들이 넘어올 지, 알 수가 없다. 따라서 Rest 파라미터를 활용해서 funcList 파라미터를 받는다.
pipe 함수는 바로 함수를 return 하는데, 이 함수는 내부적으로 funcList 의 reduce 를 돌면서, 함수의 반환값을 다음으로 넘긴다(prevFuncReturn)
다음 함수(nextFunc)는 prevFuncReturn 을 받아서 돌아가는 방식이 된다.
pipe의 funcList 에 func1, func2, func3, func4 를 넣어두고, 첫 번째 함수의 인자를 넘겨주면 pipe 가 실행된다.
Day 16-17 학습 정리
Linux File System
FHS
Linux File System Explained!(이 유튜브 영상을 참고)
초기 리눅스 버전에서는, 다양한 배포판들에서 파일 시스템의 구조가 다 달라서 굉장히 혼란스러웠다고 한다. 이렇게 혼란스러울때마다 늘 등장하는 것은 역시 인터페이스인가보다. Linux 커뮤니티는 FHS(Filesystem Hierarchy Standard, 표준 파일 시스템 계층) 을 만들어서 획일화된 계층 구조를 제공했다.
물론 배포판들마다 조금씩은 다른 경우가 있다고 하지만, 아마 큰 틀에서 벗어나지 않는 정도일 것이다.
그렇다면 FHS 에서 핵심 디렉토리들에 대해서 한 번 살펴보자.
핵심 디렉토리들
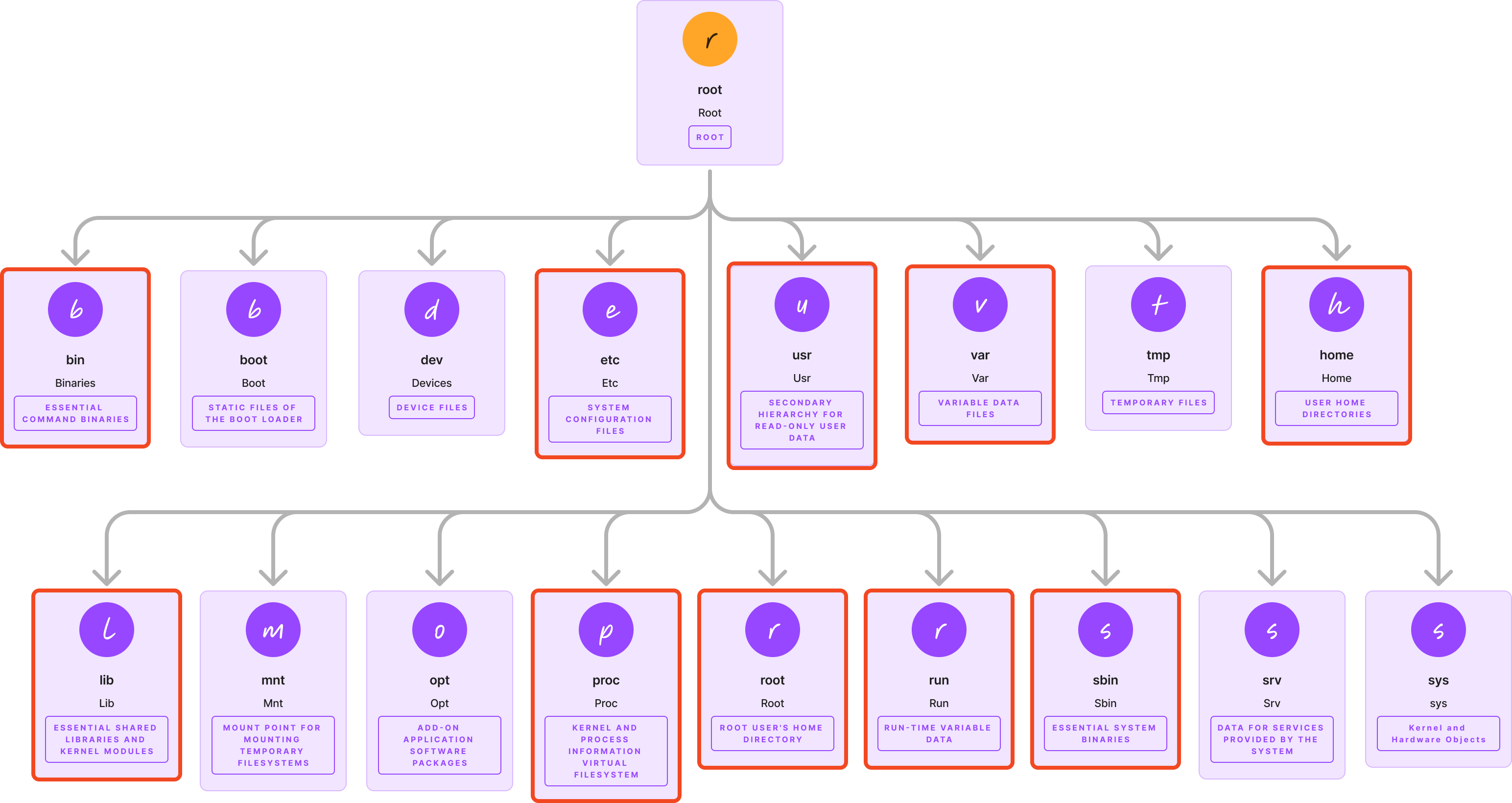 image.png
image.png
실행 가능한 바이너리 (/bin, /sbin, /usr)
첫 번째로 ‘실행 가능한 바이너리 경로들’ 인, /bin. /sbin, /usr/bin, /usr/local/bin 이다.
/bin 에는 부팅 시, /usr 이 마운트(연결) 되기 전에 액세스해야 하는 핵심 OS 프로그램이 포함되어 있다.
즉 /usr 에 해당하는 부분이 연결되기 전에 /bin 에 있는 핵심 프로그램들이 먼저 준비가 되어있어야 한다는 것이다. mount, ls, cd 등이 /bin 에 위치하고 있다.
/usr/bin 은 운영체제가 제공하는 바이너리의 경로가 아니라, 사용자의 프로그램들을 위한 바이너리가 담겨져 있다. 그렇기 때문에 usr 를 ‘user’ 로 착각할 수 있는데, usr => Unix System Resources 라고 한다.
/usr/local/bin 에는 일반적으로 소스에서 빌드한 후, 관리자가 설치한 실행 파일이 보관된다.
그렇다면 /usr/bin 과 /usr/local/bin 의 차이는 뭘까?
bin 오래된 글이긴 하지만, 스택오버플로우의 글에 따르면
/usr/bin 은 기본 패키지 매니저에서 제공되는 소프트웨어를,
/usr/local/bin 은 기본 패키지 매니저 외부에서 제공되는 소프트웨어를 저장하는 경로라고 한다.
예를 들어, 인텔 맥북의 경우에는 homebrew 를 통해 설치한 패키지들이 /usr/local/bin 에 저장되었다고 한다. (M1 이상부터는 /opt/homebrew/bin 에 저장된다고 한다.)
영상에서는 firefox, VLC(동영상 플레이어) 등으로 예시를 들었다.
/sbin 은 root 권한이 필요한 sysadmin 유틸리티(iptables, sshd, …)가 포함되어 있다.
이렇게 시스템 바이너리들을 위한 /bin 과 /usr 를 따로 분리함으로써, 시스템 바이너리들을 덮어쓰지 않고 별도로 유지할 수 있다. 추후 접근 시에는 이런 실행파일들의 경로에 대한 우선순위에 맞게 탐색하게 된다.
lib
/lib 에는 /bin, /sbin 바이너리에 필요한, 필수 라이브러리 파일들이 포함되어 있다.
/usr/lib 에는 초기 시스템 초기화에 중요하지 않은 /usr 바이너리용 라이브러리가 들어있다. 예시로 들었던 firefox 나, VLC 를 위한 라이브러리들이 굳이 시스템 초기화에 필요하지 않기 때문에 분리해놓은 것이다.
etc
etc 에는 text-based config file 들이 존재하는데, 네트워킹부터 인증 서비스까지 모든 것을 제어한다.
대표적인 예시로 우리가 자주 사용하는 /etc/ssh/sshd_config 파일이나, /etc/crontab, /etc/sudoers, /etc/network/interfaces 등이 etc 에 있다.
home
이전까지는 /usr 가 사용자 디렉토리가 왜 아닌지 몰랐지만 이제는 안다. home 디렉토리가 사실 진짜 사용자의 데이터를 저장하는 디렉토리라는 것을
문서, 미디어, 프로젝트 등등 우리가 실질적으로 자주 쓰는 파일들이 해당한다.
root
home 디렉토리가 사용자 디렉토리라면, root 디렉토리는 root 사용자의 디렉토리이다.
관리자 전용으로 사용해야하는, 일반 사용자들은 접근할 수 없도록 설계되어 있다.
var
로그 및 캐시와 같이 빠르게 변화하는 데이터는 /var 에 존재한다.
특히 /var/log 에는 하드웨어 이벤트, 보안 이슈들, 성능 문제 등등이 기록되기 때문에 늘 접근해야하는 곳이라고 한다.
run
/run 에는 시스템 세부정보, 사용자 세션, 로깅 데몬과 같은 일시적인 런타임 정보가 포함되어 있다.
예를 들면 프로세스 ID 를 저장하는 PID 파일들이나, 소켓 파일이나, 리소스 접근을 조정하는 락 파일 등이 저장된다.
이 파일들은 전부 일시적 이라는걸 생각해보면 조금 더 이해가 쉬울 것 같다.
proc, sys
proc 은 전체 OS 상태를 검사하기 위해 통신 채널을 연다. cpuinfo 를 통해 high level 측정항목을 확인하고, 파일 시스템 마운트를 확인하고, lsof / strace / pmap 과 같은 도구를 사용해서 더 자세히 살펴볼 수 있다.
sys 는 low level 커널 및 하드웨어를 노출하여, 가상 파일을 통해 장치, 모듈, 네트워크 스택과 같은 구성 요소를 세부적으로 모니터링하고 구성할 수 있다.
이렇게 proc 과 sys 에서는 메트릭을 수집할 수 있다고 하는데, 그렇다면 메트릭을 수집하는 프로메테우스나 metrics server 같은 것들은 전부 proc 과 sys 에서 수집해가는걸까?
shell
docker run -d --rm -p 9256:9256 --privileged -v /proc:/host/proc -v `pwd`:/config ncabatoff/process-exporter --procfs /host/proc -config.path /config/filename.yml
궁금해서 찾아봤더니, prometheus exporter 프로메테우스의 exporter 는 /proc 에서 정보를 mines 한다..!
Stream and Buffer
우리가 영화나 드라마를 볼 때, 길이가 1시간이 넘는 영상을 전부 로딩하는걸 기다렸다가 재생하지는 않는다. 스트리밍 이라는 용어를 쓰면서, 실시간으로 조금씩 영상이 로딩되면서 재생이 된다. 네트워크가 원활하다면 버퍼링 없이 볼 수 있을테고, 네트워크가 잠깐 끊기거나 운이 좋지 않다면 아예 새로고침까지 해서 다시 로딩해야할 수도 있다.
그렇다면 스트림과 버퍼의 의미는 뭘까? 참고 영상
Stream
Stream is a sequence of data that is being moved from one point to another over time
Stream은 시간이 흐름에 따라 한 곳에서, 다른 곳으로 이동하는 데이터들의 연속적인 흐름이다.
전체 데이터가 전부 도착하기를 기다리기 보다는, 도착한 데이터 덩어리(chunk)들의 stream을 바로 process 한다.
데이터를 한 번에 메모리에 담아놓고 처리하지 않기 때문에, 메모리 사용량 면에서 효율적이다.
그렇다면 이 sequences of data 가 어떻게 움직이는 걸까?
Buffer
버퍼는 데이터들을 저장하고 있는 임시 공간이다.
혹시 유튜브 영상을 볼 때 버퍼링이 걸려서 로딩이 걸려본 적이 있다면 이해가 조금 더 쉬울 것 같다.
인터넷 속도가 느려져서 버퍼에 영상을 플레이할 만큼의 데이터가 들어있지 않다면, 데이터가 조금 더 도착할때까지 로딩을 하는 것이다.
그렇게 버퍼가 가득차면 그 만큼의 영상을 우리가 볼 수 있게 되고 만약 앞선 버퍼만큼의 영상을 다 보는 동안 다음 버퍼가 채워지지 않았다면 또 대기를 하게 된다.
이번엔 node.js 코드로 버퍼에 대해서 한 번 살펴보자.
javascript
const buffer = new Buffer.from("what the hello world", "utf-8"); // String을 받아서 문자열 인코딩에 맞는 Buffer 객체 생성
console.log(buffer);
console.log(buffer.toJSON());
/*
두 출력값이 다른 이유는, buffer 에는 16진수로 담겨져있고 toJson 에는 아스키코드에 해당하는 숫자로 담겨있기 때문이다. 77(16) -> 119(10)
<Buffer 77 68 61 74 20 74 68 65 20 68 65 6c 6c 6f 20 77 6f 72 6c 64>
{
type: 'Buffer',
data: [
119, 104, 97, 116, 32, 116, // w, h, a, t, ' ', t
104, 101, 32, 104, 101, 108, // h, e, ' ', h, e, l
108, 111, 32, 119, 111, 114, // l, o, ' ', w, o, r
108, 100 // l, d
]
}
*/
이번에는 buffer 에 write 하면서 어떤 일이 생기는지 살펴보자.
javascript
const buffer = new Buffer.from("what the hello world", "utf-8"); // String을 받아서 문자열 인코딩에 맞는 Buffer 객체 생성
console.log(buffer.toString());
console.log(buffer);
console.log(buffer.toJSON());
buffer.write("abcdefg");
console.log(buffer.toString());
buffer.write("abcdefghijklmnopqrstuvwxyz");
console.log(buffer.toString());
/*
what the hello world
<Buffer 77 68 61 74 20 74 68 65 20 68 65 6c 6c 6f 20 77 6f 72 6c 64>
{
type: 'Buffer',
data: [
119, 104, 97, 116, 32, 116,
104, 101, 32, 104, 101, 108,
108, 111, 32, 119, 111, 114,
108, 100
]
}
abcdefge hello world
abcdefghijklmnopqrst
*/
buffer.write(string)은 버퍼에 덮어쓰기를 실행하는데 보다시피 what the hello world -> abcdefge hello world 로 바뀐 것을 볼 수 있다. 이는 앞에서부터 덮어쓰기를 실행한 결과이다.
두 번째로 buffer.write(“abcdefghijklmnopqrstuvwxyz”); 를 실행했더니 abcdefge hello world -> abcdefghijklmnopqrst 로 바뀐 것을 볼 수 있다.
분명히 …xyz 까지 write 를 했는데 …pqrst 까지 밖에 write 되지 않은 것을 볼 수 있다. 이는 buffer.from(“what the hello world”)로 버퍼 객체를 만들면서 최대 크기를 “what the hello world” 크기로 지정한 것이기 때문이다.
초과한 양은 전부 버려진다. -> 버퍼 오버플로우
Buffer 와 Stream 은 그래서 무슨 관계가 있는거야?
우선! 알아두면 좋은 것은 Stream은 EventEmitter 의 instance 이다. Stream 에서 버퍼가 가득찼는지 등의 이벤트 가 발생하고 이를 Listener 함수로 처리할 수 있다.
아래에서 한 번 더 설명하겠지만 미리 알고 있으면 좋을 것 같다.
node.js 의 Stream은 스트리밍 데이터를 처리하기 위한 인터페이스로, 4가지의 타입이 있다.
- Writable: streams to which data can be written (for example, fs.createWriteStream()).
- Readable: streams from which data can be read (for example, fs.createReadStream()).
- Duplex: streams that are both Readable and Writable (for example, net.Socket).
- Transform: Duplex streams that can modify or transform the data as it is written and read (for example, zlib.createDeflate()).
Stream 은 위에서 언급했던 것처럼 다른 곳으로 이동하는 데이터들의 연속적인 흐름이라는 추상화된 개념 이고, 그 데이터들을 담고 있는 것이 버퍼이다.
하지만 이것만으로는 node.js 에서 어떻게 활용해야할지 감이 잘 안잡혀서, node.js 의 stream 이 어떤 방식으로 동작하는지 조금 이해해보기 위해 공식 문서를 읽어보면서 각 타입이 어떤건지 알아보자. stream buffering
The amount of data potentially buffered depends on the highWaterMark option passed into the stream’s constructor. For normal streams, the highWaterMark option specifies a total number of bytes. For streams operating in object mode, the highWaterMark specifies a total number of objects. For streams operating on (but not decoding) strings, the highWaterMark specifies a total number of UTF-16 code units.
우선 highWaterMark 라는 Stream 생성자의 옵션을 통해서 내부 버퍼의 사이즈를 정해줄 수 있다. 또한 normal, object mode, string 마다 highWaterMark 가 의미하는 바가 조금씩 다르다고 한다.
Readable Stream
Data is buffered in Readable streams when the implementation calls stream.push(chunk). If the consumer of the Stream does not call stream.read(), the data will sit in the internal queue until it is consumed.
Once the total size of the internal read buffer reaches the threshold specified by highWaterMark, the stream will temporarily stop reading data from the underlying resource until the data currently buffered can be consumed (that is, the stream will stop calling the internal readable._read() method that is used to fill the read buffer).
Readable stream 에서는 stream.push(chunk) 를 호출할 때마다 데이터를 읽고 내부 버퍼에 데이터를 쌓는다. 따로 consumer 가 stream.read() 로 데이터를 소비하지 않는 이상, 쭉 누적 된다. 그러다가 만약 내부 버퍼의 사이즈가 highWaterMark 에 도달하게 되면 스트림은 버퍼에 쌓인 데이터들이 소비될때까지 “데이터를 읽고 버퍼에 쌓는 과정”(=>readable._read())을 멈춘다.
event
Readable Stream 에는 close, data,end, error, pause, readable, resume 이벤트가 있다.
바로 위의 Readable Stream 링크를 눌러서 공식문서를 확인해보면 자세히 나와있어서 알아두어야 할 이벤트만 정리해보려고 한다.
-
data
data 이벤트는 stream 이 데이터를 읽어올 처리할 준비가 되었을 때 발생하는 이벤트이다. 어떤 상태인지 알아봤더니,
스트림에서 새로운 데이터가 읽혀질 때마다 data 이벤트가 발생한다고 한다.
-
readable
The ‘readable’ event is emitted when there is data available to be read from the stream, up to the configured high water mark (state.highWaterMark). Effectively, it indicates that the stream has new information within the buffer. If data is available within this buffer, stream.read() can be called to retrieve that data. Additionally, the ‘readable’ event may also be emitted when the end of the stream has been reached.
readable 이벤트는 스트림으로부터 데이터를 읽을 수 있을 때 호출된다. 스트림의 버퍼에 읽을 수 있는 데이터가 존재한다는 뜻이되고, stream.read() 로 데이터를 소비할 수 있다. 추가로 스트림의 끝에 도달했을때도 readable 이벤트가 한 번 더 호출된다고 한다.
다시 한 번 이벤트가 발생하는게 조금 의아해서 chatgpt 에게 물어본 결과인데, 참고만 하자.
참고용 Chatgpt
1. 버퍼에 남아있는 데이터 처리 마지막 데이터 조각: 스트림이 끝나기 직전에 버퍼에 일부 데이터가 남아 있을 수 있습니다. 이 남은 데이터를 처리하기 위해 'readable' 이벤트가 한 번 더 발생하는 것입니다. 완전한 처리: 스트림에서 모든 데이터를 정확하게 처리하기 위해서는 버퍼에 남아있는 마지막 데이터 조각까지 처리해야 합니다. 2. 스트림 종료 시점 명확화 스트림 종료 신호: 'readable' 이벤트와 함께 스트림의 종료를 알리는 추가적인 신호가 제공될 수 있습니다. 예를 들어, end 이벤트가 발생하면 스트림이 완전히 종료되었다는 것을 알 수 있습니다. 안정적인 종료: 스트림의 종료 시점을 명확하게 하여 프로그램의 안정성을 높일 수 있습니다. 3. 데이터 처리 로직 완성 마무리 작업: 스트림이 끝나기 전에 마무리해야 할 작업이 있을 수 있습니다. 예를 들어, 파일을 닫거나 연결을 해제하는 작업이 필요할 수 있습니다. 'readable' 이벤트를 통해 이러한 마무리 작업을 수행할 수 있습니다. 4. 스트림의 특성 비동기 처리: 스트림은 비동기적으로 데이터를 처리하기 때문에, 실제로 데이터가 모두 읽혀졌더라도 이벤트 루프에서 처리되는 데 약간의 시간이 걸릴 수 있습니다. 버퍼링: 스트림은 내부적으로 버퍼를 사용하여 데이터를 관리합니다. 버퍼의 크기나 스트림의 설정에 따라 'readable' 이벤트 발생 시점이 달라질 수 있습니다. 즉, 스트림 끝에 도달했음에도 불구하고 'readable' 이벤트가 발생하는 것은 버퍼에 남아있는 데이터를 처리하고, 스트림의 종료를 명확하게 하기 위한 메커니즘입니다.
Writable Stream
Data is buffered in Writable streams when the writable.write(chunk) method is called repeatedly. While the total size of the internal write buffer is below the threshold set by highWaterMark, calls to writable.write() will return true. Once the size of the internal buffer reaches or exceeds the highWaterMark, false will be returned.
Writable Stream 에서는 writable.write(chunk) 를 반복적으로 호출하면서 내부 버퍼에 데이터를 쌓는다.
만약 내부 버퍼의 용량이 아직 highWaterMark 를 넘지 않는다면 true 를, 넘는다면 false 를 반환하는데,
반복적으로 writable.write(chunk) 를 수행하다가 false 가 반환되면 더 이상 버퍼에 쓰는걸 멈추고 fs 같은 파일시스템으로 작성한다든지의 처리를 하면 된다.
event
Writable Stream 에는 close, drain, error, finish, pipe, unpipe 이벤트가 있다.
마찬가지로 Writable Stream 링크를 눌러서 공식문서를 확인해보면 자세히 나와있어서 알아두어야 할 이벤트만 정리해보려고 한다.
-
drain
If a call to stream.write(chunk) returns false, the ‘drain’ event will be emitted when it is appropriate to resume writing data to the stream.
drain 이벤트는 stream.write(chunk) 의 결과값이 false 일때(버퍼가 가득 찼을 때)가 되고난 후, 데이터가 잘 소비되어서 버퍼에 공간이 생겨서 다시 쌓을 준비가 되는 순간이 있을 것이다. 이때 drain 이벤트가 emit 된다.
버퍼가 가득 찼을 때 호출 되는 이벤트가 아니다. 버퍼에 다시 데이터를 저장할 수 있는 순간에 호출이 되는 것이다.
-
pipe
Readable stream 에서 stream.pipe() 를 호출 했을 때 발생하는 이벤트이다. Readable stream 에서 읽은 데이터를 파이프를 통해 넘겨주기 위해서, 파이프를 연결한 것이다.
-
unpipe
pipe 와 반대로 Readable stream 이 연결된 writable stream 과의 pipe 를 끊어낼 때 호출되는 이벤트이다.
Duplex, Transform
Because Duplex and Transform streams are both Readable and Writable, each maintains two separate internal buffers used for reading and writing, allowing each side to operate independently of the other while maintaining an appropriate and efficient flow of data. For example, net.Socket instances are Duplex streams whose Readable side allows consumption of data received from the socket and whose Writable side allows writing data to the socket. Because data may be written to the socket at a faster or slower rate than data is received, each side should operate (and buffer) independently of the other.
Duplex 와 Transforrm stream 은 Readable 과 Writable 이 동시에 가능한 stream 이다. 따라서 내부 버퍼도 2개(read, write) 를 가지고 있다. 두 개의 내부 버퍼는 독립적으로 동작하므로 효율성이 좋다고 한다.
예를 들어 Duplex 의 인스턴스인 net.Socket 은 소켓으로부터 읽은 데이터를 소비하는 Readable, 소켓으로 데이터를 write 하는 두 개의 내부 버퍼가 각각 독립적으로 동작한다. 데이터의 쓰기와 읽기가 속도 차이가 날 수 있기 때문에 서로 독립적으로 작동해야 한다고 한다.
Stream 의 목적
A key goal of the stream API, particularly the stream.pipe() method, is to limit the buffering of data to acceptable levels such that sources and destinations of differing speeds will not overwhelm the available memory.
Stream API, stream.pipe 의 궁극적인 목표는 데이터의 버퍼링을 어느정도 수준으로 제한해서 데이터를 보내는 쪽과 받는 쪽의 속도 차이가 나도, 메모리 사용량을 초과하지 않게끔 하는 것이다.
데이터를 빠르게 받거나 보내는 경우에도, 데이터를 중간에 너무 많이 쌓아두지 않고 바로바로 처리해서 메모리를 효율적으로 사용한다는 의미로 받아들이면 될 것 같다.
stream.pipe() 도 마찬가지의 역할을 하는 것 같다.
그래서 node.js 에서 어떻게 활용해?
stream 이 readable, writable 을 통해서 버퍼에 데이터를 저장한다는 것 까지는 이해를 했다. 보통 stream 을 활용하는 곳이 HTTP 통신이거나 파일일 것 같아서 파일을 읽고 쓰는 방법을 한 번 알아보려고 한다.
createReadStream
javascript
import fs from "fs";
const readStream = fs.createReadStream("inputFile.txt", "utf8");
readStream.on("data", (chunk) => {
console.log("data", chunk);
});
readStream.on("end", () => {
console.log("end");
});
javascript
import fs from "fs";
const readStream = fs.createReadStream("inputFile.txt", "utf8");
readStream.on("readable", () => {
let chunk;
while (null !== (chunk = readStream.read(15))) {
console.log(chunk);
}
});
readStream.on("end", () => {
console.log("end");
});
readStream 의 data 이벤트와 readable 이벤트 모두 데이터를 버퍼로부터 읽어올 수 있는데, data 의 경우 chunk 가 그대로 리스너 함수에 넘어온다.
반면 readable 이벤트는 read() 를 통해서 직접 읽어야하는데, 이때 얼만큼 읽을지 정할 수 있다.
createWriteStream
javascript
import fs from "fs";
const writeStream = fs.createWriteStream("outputFile.txt", { highWaterMark: 50 });
writeStream.on("drain", () => console.log("buffer ready"));
setInterval(() => {
while (writeStream.write("hello world"));
}, 1000);
writeStream 에서는 어떤 방식으로 동작하는지 확인해보려고 일부러 버퍼의 크기를 50으로 제한했다.
이후에 1초마다 writeStream 에 “hello world” 라는 문자열을 write 를 시도하는데, 위에서 적은 것 처럼 drain 이벤트는 writeStream.write() 가 false 인 상태에서,
다시 버퍼에 무언가 적는게 가능할 때 호출된다.
이대로 코드를 돌려보면 hello world 를 사이즈가 50이 될 때 까지 write 하고, 주기적으로 버퍼에 공간이 생길때마다 “buffer ready” 라는 출력이 찍힌다. 이후에 또 hello world 가 write 되고 계속 반복된다.
위의 코드는 drain 이벤트 실험을 위해서 작성한 코드이고, 실제로 파일을 작성할 때는 아래처럼 진행하면 된다.
javascript
import fs from "fs";
const writeStream = fs.createWriteStream("outputFile.txt", { highWaterMark: 50 });
writeStream.write("hello world");
writeStream.end();
pipe
javascript
import fs from "fs";
const readStream = fs.createReadStream("inputFile.txt", { highWaterMark: 5 });
const writeStream = fs.createWriteStream("outputFile.txt", { highWaterMark: 5 });
writeStream.on("drain", () => console.log("drain"));
readStream.pipe(writeStream);
readStream 의 버퍼에서 읽어온 값을 바로 writeStream 의 내부 버퍼로 들어가게 된다.
출력해보면 지속적으로 drain 로그가 찍힌다.
Day 18-19 학습 정리
Telnet vs SSH
Telnet
텔넷은 원격 서버에 액세스하기 위해 사용되는 터미널 에뮬레이션 프로그램이다.
터미널로 명령을 이용하여 서버에 수행 할 작업을 지시할 수 있다. 또한 라우터 및 스위치와 같은 다른 네트워크 장치를 관리하고 구성하는데도 사용할 수 있다.
1969년에 개발되었다보니 서버로 전송하는 명령에 암호화 같은 것은 없다.
SSH
SSH는 Secure Shell 로, 텔넷보다 보안이 강화되었다. 암호화 및, 공개 키 인증을 통해 데이터를 갈취당하지 않고 안전하게 서버로 보낼 수 있다.
통신 프로토콜
TCP
연결 지향이라서 연결 과정이 필요하다.
- 서버(소켓) 생성
- 서버와 클라이언트 소켓을 연결
node.js
net.Server 소켓 서버 클래스 -> 서버 (eventEmitter) net.Socket 소켓 클래스 -> 서로 연결하는 스트림(duplex)
javascript
/*
const server = net.createServer([options][,connectionListener]);
server.listen(port[,host][,backlog][,callback]) // 클라이언트 접속 대기
server.close([callback])
server.getConnections(callback)
server.address() : 서버 주소
*/
// 서버 측
const server = net.createServer((socket) => {
// connection 이벤트 리스너 함수
});
server.on("listening", () => {});
server.on("close", () => {});
// 클라이언트 측
const socket = new net.Socket();
const option = {
host: "localhost",
port: 3000,
};
socket.connect(option, () => {});
net.Server event
- listening : 포트 바인딩, 접속 가능한 상태 이벤트
conneciton: 클라이언트 접속 이벤트- close : 서버 닫을 때
- error: 에러
net.Socket event
- connect
- data : stream data 이벤트
- end
- timeout
- error
세션? JWT?
쿠키
서버에서 클라이언트에 대한 정보를 기록해두기 위해서, 클라이언트의 브라우저에 저장하는 데이터
클라이언트에서 서버에 요청을 보내고, 응답을 받았을 때 쿠키가 들어있을 수 있다. 이후 서버에 요청을 보낼 때, 브라우저는 계속 자동으로 쿠키를 담아서 요청을 보내게 된다.
쿠키는 도메인에 따라 제한되기 때문에, 쿠키를 받은 서버에만, 해당 쿠키를 보낸다. 쿠키는 아래의 세션ID 를 담고있는 매개체이기도 하다.
쿠키는 사이즈에 제약이 있다.
세션
HTTP 프로토콜은 stateless 이다. stateless 라는 의미는, 이전의 리퀘스트와 현재의 리퀘스트는 독립적으로 이루어진다는 의미이다.
서버에서 요청에 대한 처리를 하고 클라이언트가 응답을 받으면, 새로운 요청을 보낼 때마다 클라이언트는 자신의 정보를 담아서 보내야 한다.
서버에서 세션 DB에 데이터를 저장하고, 해당 세션의 ID를 클라이언트에게 돌려준다. 클라이언트의 브라우저는 쿠키에 세션 ID 를 저장하고 있다가,
앞으로 있을 요청에 계속 세션 ID와 함께 보낸다.
서버는 쿠키에 담긴 세션 ID를 가지고 세션 DB를 탐색하여 사용자의 정보를 찾아낸다.
유저는 세션 ID만 보내게 되면 서버가 알아서 세션 ID를 가지고 사용자의 정보를 알아내기 때문에, 클라이언트 입장에서 매우 편해진다.
세션에서 가장 중요한 것은, 서버에서는 현재 로그인한 유저들의 모든 세션 ID 값을 DB에 저장하고 있어야 한다.
토큰
세션ID를 담아서 보내기 위해서는 쿠키가 필요하다. 그러나 쿠키는 브라우저에만 있기 때문에, 앱 어플리케이션에서는 쿠키를 이용할 수 없다.
따라서 앱 어플리케이션에서 세션을 구현하기 위해서는 쿠키 대신 토큰을 이용한다.
토큰은 그저 String 인데, 서버는 이 토큰과 일치하는 유저 정보를 세션 DB에서 찾아낸다.
JWT(Json Web Tokens)
JWT도 이름에서 알 수 있는 것처럼, 토큰 형식이다.
대신 다른점은, 서버에서 세션 DB를 가지고 있을 필요가 없다. 서버는 토큰을 가지고 유저 인증(사용자 정보)을 위해서 이런 저런 일을 할 필요가 없다.
사용자가 로그인을 하게 되면, 세션은 로그인 중인 사용자의 정보를 DB에 저장하는 반면, JWT는 따로 DB에 저장하지 않는다.
대신 어떠한 정보(예를 들면 유저의 ID)를 기반으로 사인 알고리즘을 이용해서 사인을 한다. 이후 사인된 정보를 문자열 형태로 클라이언트에게 돌려준다.
JWT는 사이즈에 제약이 없어서 길어도 된다.
JWT를 발급받고 나서 다시 서버에 로그인을 하려면, JWT 토큰 혹은 사인된 정보 를 서버에 보내야한다.
보통 JWT토큰을 다시 보내서 서버가 받으면 해당 사인이 유효한지 체크해서 토큰이 유효하다면 사용자 인증을 하게 된다.
즉 JWT에서는 유저를 인증하는데 필요한 정보가 전부 토큰에 담겨있다. 토큰에는 길이의 제한이 없기 때문에.
토큰이 유효하다면, 사용자도 유효하다는 뜻이다.
JWT는 암호화된 문자열이 아니다. 암호화가 되어 있으면 이를 읽고 이해할 수가 없기 때문이다.
따라서 누구나 JWT 토큰을 열어서 확인할 수 있다. 따라서 JWT 토큰에는 비밀번호 같은 것이 담기면 안된다.
세션 vs JWT
세션은 서버에서 유저의 정보를 가지고 있기 때문에 다양한 추가 기능을 구현할 수 있다. 대신 DB에 저장을 해야하는 만큼 메모리가 필요하다. JWT는 토큰 자체에 유저를 인증할 수 있는 정보가 있기 때문에 유저 인증을 위한 DB가 필요하지 않다.
JWT 토큰은 만료되기 전까지는 무조건 유효하다. 그렇기 때문에 이 토큰이 현재 유효한지, 아닌지만을 판별할 수 있지 다른 것이 불가능하다.
UUID
UUID는 ‘Universally Unique Identifier’의 약자로 128bit 의 고유 식별자이다.
이전에 공부했던 SHA-256이 생각났었는데, 실제로 UUID 의 여러 버전 중에 해싱 알고리즘을 쓰는 버전이 있다고 한다.
신기한게 버전별로 UUID가 생성되는 방식이 다른데, 이를 생각보다 주의해서 생성해야 할 것 같다.
UUID v1, UUID v2 버전은 타임스탬프 UUID 라고 부르는데, UUID가 만들어진 시점과 기기 정보를 토대로 UUID가 만들어지는 것 같다.
UUID v3, UUID v5 버전은 네임스페이스 UUID로, 해싱 알고리즘을 통해서 암호화된 UUID 가 생성된다. v3는 MDA, v5 는 SHA-1 알고리즘을 기반으로 생성된다고 한다.
UUID v4는 랜덤값을 기반으로 생성된다.
Subscribe to hoeeeeeh
Get the latest posts delivered right to your inbox
